Chapter 31 Spatially Continuous Data I
In this chapter you will use a custom function that is included in the package isdas as follows:
kpointmeans(source_xy, target_xy, z, k, latlong)
This is a function to calculate \(k\)-point means. It takes a simple features object with the variable that we wish to interpolate (source_xy), that is, the coordinates of observations to be used for interpolation; the variable z to interpolate should be a column in source_xy; a simple features object with the points where we wish to interpolate variable z (target_xy); the number of nearest neighbors k; and a logical value to indicate whether the coordinates are latitude-longitude (the default is FALSE).
31.1 Learning objectives
Previously, you learned about the analysis of area data. Starting with this practice, you will be introduced to another type of spatial data: continuous data, also called fields. In this practice, you will learn:
- About spatially continuous data/fields.
- Exploratory visualization.
- The purpose of spatial interpolation.
- The use of tile-based approaches.
- Inverse distance weighting.
- K-point means.
31.2 Suggested readings
- Bailey TC and Gatrell AC (1995) Interactive Spatial Data Analysis, Chapters 5 and 6. Longman: Essex.
- Bivand RS, Pebesma E, and Gomez-Rubio V (2008) Applied Spatial Data Analysis with R, Chapter 8. Springer: New York.
- Brunsdon C and Comber L (2015) An Introduction to R for Spatial Analysis and Mapping, Chapter 6, Sections 6.7 and 6.8. Sage: Los Angeles.
- Isaaks EH and Srivastava RM (1989) An Introduction to Applied Geostatistics, Chapter 4. Oxford University Press: Oxford.
- O’Sullivan D and Unwin D (2010) Geographic Information Analysis, 2nd Edition, Chapters 9 and 10. John Wiley & Sons: New Jersey.
31.3 Preliminaries
As a reminder, it is good practice to begin with a new R session or to at least clear the working space to make sure that you do not have extraneous items there when you begin your work. The command in R to clear the workspace is rm (for “remove”), followed by a list of items to be removed. To clear the workspace from all objects, do the following:
Note that ls() lists all objects currently on the workspace.
Load the libraries you will use in this activity:
library(deldir) # Delaunay Triangulation and Dirichlet (Voronoi) Tessellation
library(isdas) # Companion Package for Book An Introduction to Spatial Data Analysis and Statistics
library(plotly) # Create Interactive Web Graphics via 'plotly.js'
library(spatstat) # Spatial Point Pattern Analysis, Model-Fitting, Simulation, Tests
#library(spatstat.explore) # Exploratory Data Analysis for the 'spatstat' Family
library(spdep) # Spatial Dependence: Weighting Schemes, Statistics
library(tidyverse) # Easily Install and Load the 'Tidyverse'Begin by loading the data you will need for this Chapter:
You can verify the contents of the dataframe:
## ID X Y V
## Length:470 Min. : 8.0 Min. : 8.0 Min. : 0.0
## Class :character 1st Qu.: 51.0 1st Qu.: 80.0 1st Qu.: 182.0
## Mode :character Median : 89.0 Median :139.5 Median : 425.2
## Mean :111.1 Mean :141.3 Mean : 435.4
## 3rd Qu.:170.0 3rd Qu.:208.0 3rd Qu.: 644.4
## Max. :251.0 Max. :291.0 Max. :1528.1
##
## U T
## Min. : 0.00 1: 45
## 1st Qu.: 83.95 2:425
## Median : 335.00
## Mean : 613.27
## 3rd Qu.: 883.20
## Max. :5190.10
## NA's :195This dataframe includes a sample of of geocoded observations with false coordinates X and Y, of two quantitative variables V, U, and a factor variable T. The variables are generic, but you can think of them as measurements of pollutants. The Walker Lake dataset originally was used for teaching geostatistics in Isaaks and Srivastava’s (1989) book An Introduction to Geostatistics.
31.4 Spatially continuous (field) data
Previously in the book we discussed two types of data that are of interest in spatial analysis: points and events, and areas.
The last section of the course will deal with a third type of data that finds numerous applications in many disciplines.
We will begin by recalling that there are different units of support for spatial data. The unit of support is the type of spatial object that is used to represent a spatial phenomenon, and that is useful to understand the kind of process and the types of analysis that can be applied.
In the case of point pattern analysis, the unit of support is the point. Depending on the scale of the analysis, the point could be anything from the centroid of cells, the location of trees, the addresses of businesses, or the centers of cities at a much larger scale. Obviously, none of these objects are actual points (the point is a theoretical object). However, points are a reasonable representation for events when their size is minuscule compared to the area of the region under analysis. The most basic attribute of an event is whether it is present (e.g., is there a tree at this location?). Other attributes are conditional on that one.
In the case of areas, the unit of support is a zone. Data in this type of analysis may or not be generated by a discontinuous process, but once it has been cast in the form of statistics for areas, this will usually involve discontinuities at the edges of the areas.
An important difference between point pattern analysis and analysis of data in areas is the source of the randomness.
In the case of point pattern analysis, the coordinates of the event are assumed to be the outcome of a random process. In area data, the locations of the data are exogenously given, and the source of randomness instead is in the values of the attributes.
This brings us to spatially continuous data.
Superficially, spatially continuous data looks like points. This is because of how a field is measured at discrete locations. The underlying process, however, is not discrete, and a field can in principle be measured at any location in the space where the underlying phenomenon is in operation. Some obvious examples of this include temperature and elevation. Temperature is measured at discrete locations, but the phenomenon itself is extensive. Same thing with elevation.
The source of randomness in the case of fields is the inherent uncertainty of the outcome of the process at locations where it was not measured. Therefore, an essential task is to predict values at unmeasured locations. We call this task spatial interpolation. In addition, we often are interested in assessing the degree of uncertainty of predictions or interpolated values.
The study of continuous data has been heavily influenced by the work of South African mining engineer D.G. Krige, who sought to estimate the distribution of minerals based on samples of boreholes. Since then, the study of fields has found applications in remote sensing, real estate appraisal, environmental science, hydrogeology, and many other disciplines.
We will define a field as a mixed spatial process that depends on the coordinates \(u_i\) and \(v_i\), in addition to a vector of covariates \(\bf{x}_i\): \[ z_i = f(u_i, v_i, \bf{x}_i) + \epsilon_i \] where \(i\) is an arbitrary location in the region, and \(\epsilon_i\) is the difference between the systematic description of the process (i.e., \(f(u_i, v_i, \bf{x}_i)\)) and the value of the field \(z\).
More simply, a field could be the outcome of a purely spatial process as follows: \[ z_i = f(u_i, v_i) + \epsilon_i \]
The value of a field is known at the locations \(i\) where it is measured. In locations where the field was not measured (we will call any such location \(p\)), there will be some uncertainty about the value of the field variable, which stems from our limited knowledge of the underlying process. As a consequence, there will be a random term associated with any prediction of the value of the field: \[ \hat{z}_p = \hat{f}(u_p, v_p) + \hat{\epsilon}_p \] We use the hat notation to indicate that these are estimates of the true values.
A key task in the analysis of fields is to determine a suitable function for making predictions \(\hat{z}_p\) and to estimate the uncertainty as well.
In this and upcoming sessions you will learn about methods to achieve this task.
31.5 Exploratory visualization
We will begin our discussion of fields with techniques for exploratory visualization. The methods are very similar to those used for marked point patterns in point pattern analysis. Like we did there, we can use dot or proportional symbol maps. For example, we can create a proportional symbol map of the variable V in the Walker Lake dataset (with alpha = 0.5 for some transparency to mitigate the overplotting):
ps1 <- ggplot(data = Walker_Lake,
aes (x = X, y = Y, color = V, size = V)) +
# `alpha` is used to control the transparency of the objects,
# with 1 being completely opaque and 0 completely transparent.
geom_point(alpha = 0.5) +
scale_color_distiller(palette = "OrRd",
direction = 1) +
# `Coord_equal()` ensures that units in the x and y axis are displayed using
# the same aspect ratio 1:1
coord_equal()
ps1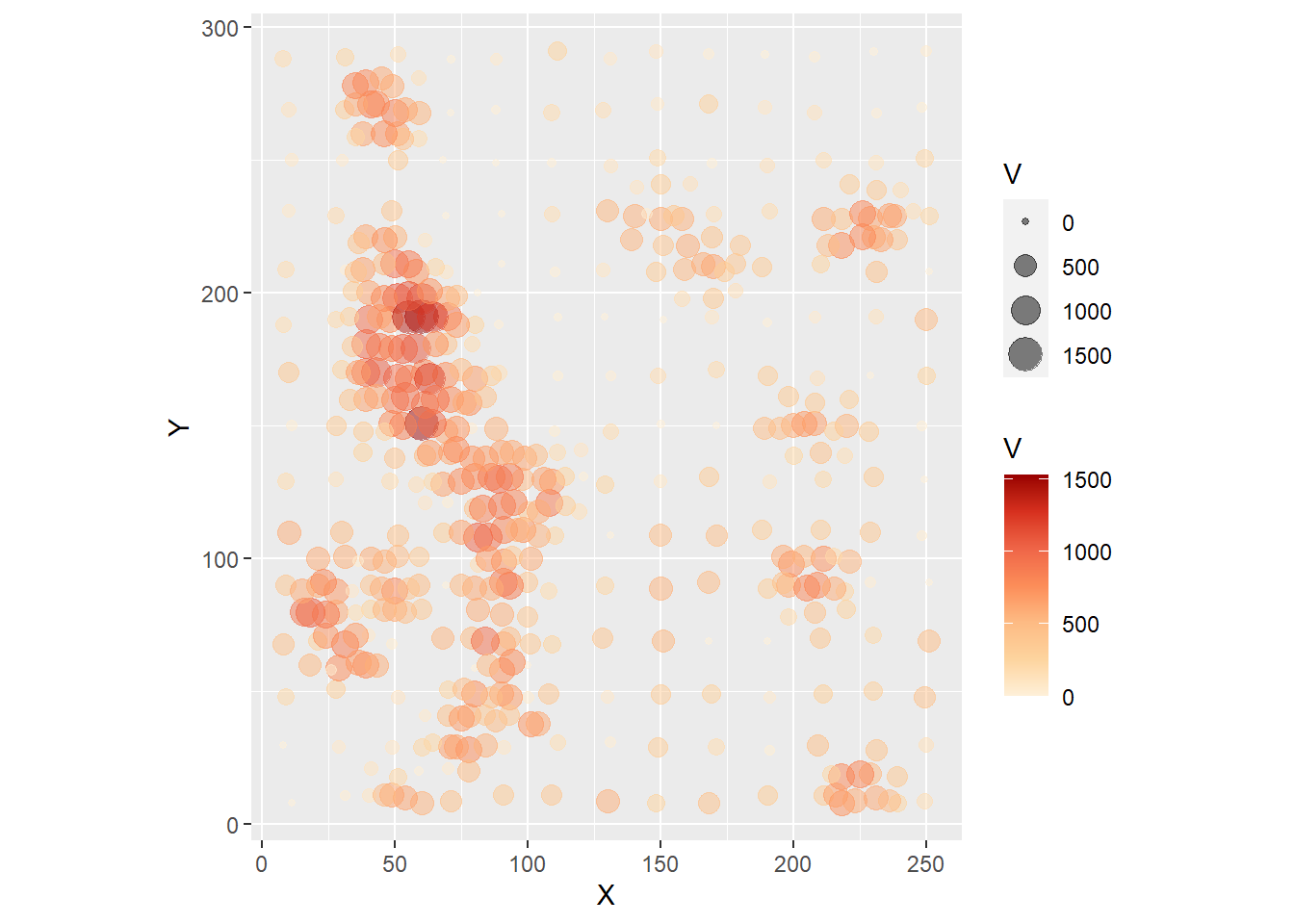
The proportional symbols indicate the location where a measurement was made. There is no randomness in these locations, as they were selected by design. In particular, notice how a regular grid seems to have been used for part of the sampling, and then possibly there was further infill sampling at those places where the field appeared to vary more.
Imagine that the observations are of a contaminant. The task could be to calculate the total amount of the contaminant over the region. This would require you to obtain estimates of the contaminant in all the region, not just those places where measurements were made. If, as is typically the case, making more observations is expensive, other approaches must be adopted.
Before proceeding, remember that the package plotly can be used to enhance exploratory analysis by allowing user interactivity. Below is the same plot as before, but now as an interactive 3D scatterplot:
31.6 Tile-based methods
Another common approach to visualize fields is by means of tile-based methods. These methods take a set of points and convert them into a tessellation, thus giving them the aspect of “tiles”.
A widely used algorithm to convert points into tiles is called Voronoi polygons, after Georgy Voronoi, the mathematician that discovered it. To illustrate how Voronoi polygons are created, we will use a simple example.
- Given a set of generating points \(p_g\) with coordinates \((u_g, u_g)\) (for \(g = 1,...,n\)) and values of a variable \(z_{p_g}\):
# Create a set of coordinates for the example
uv_coords <- matrix(c(0.7, 5.2, 3.3, 1.3, 5.4, 0.5, 1.8, 2.3, 4.8, 5.5), c(5, 2)) |>
st_multipoint("XY")
# Create a window for the points, this is similar to the windows
# used in `spatstat` for spatial point pattern analysis
box = st_polygon(list(rbind(c(0,0),c(6,0),c(6,6),c(0,6),c(0,0))))
# Create a plot of the coordinates and the window
p <- ggplot(data = uv_coords) +
geom_sf(size = 2) +
geom_sf(data = box,
fill = NA)
p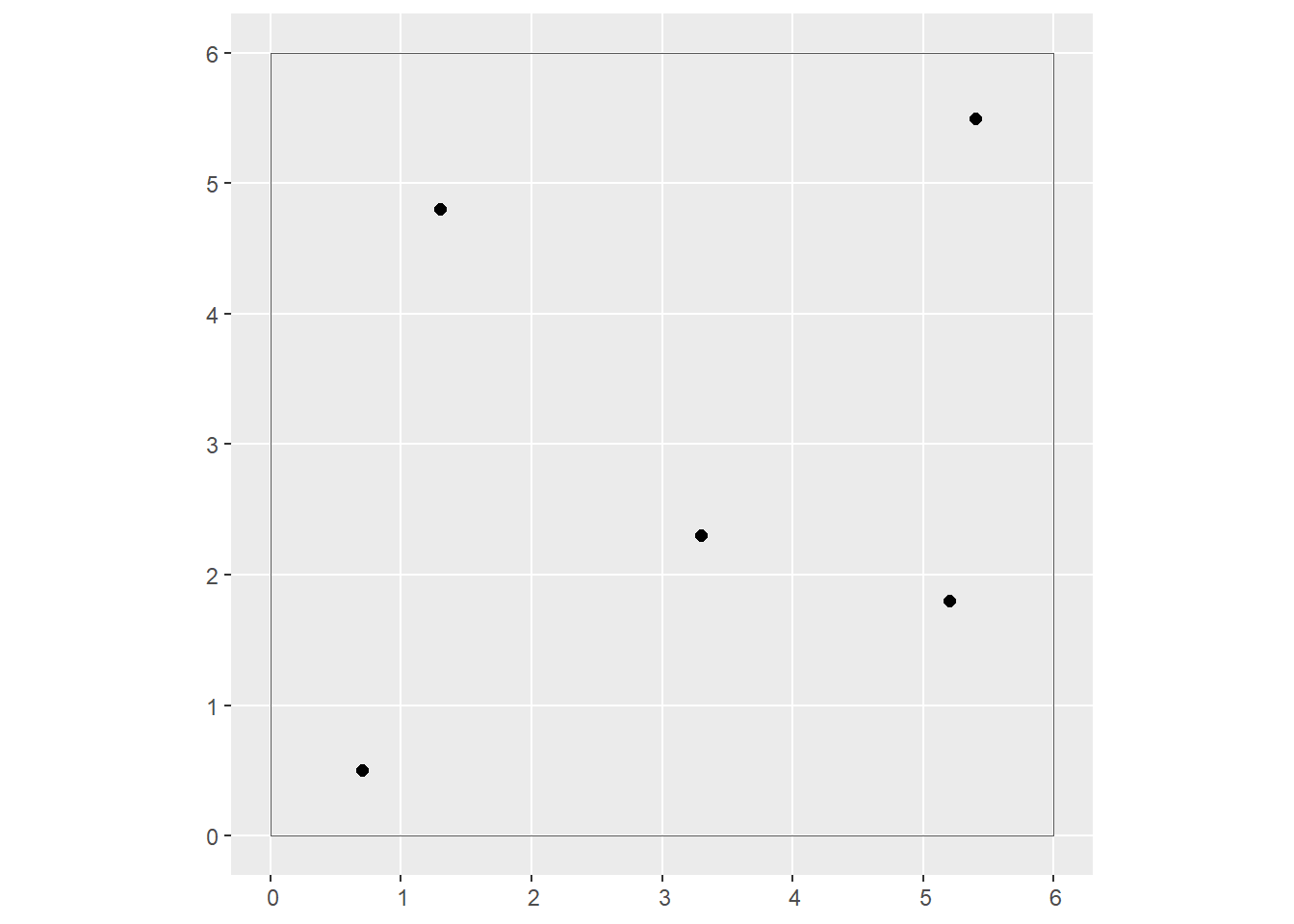
- Each point is connected by means of straight lines to its two nearest neighbors to create a triangulation:
# Create a triangulation that connect each point to its two
# nearest neighbors. The function `st_triangulate()` from
# the `sf` package does this. The output can be polygons
# (triangles) or lines only. We set bOnlyEdges = TRUE to
# obtain only the lines.
l2n <- st_triangulate(uv_coords, bOnlyEdges = TRUE)
# Plot the triangulation, i.e., the lines between nearest neighbors
ggplot(data = uv_coords) +
geom_sf(size = 2) +
geom_sf(data = box,
fill = NA) +
geom_sf(data = l2n,
color = "gray",
linetype = "dashed")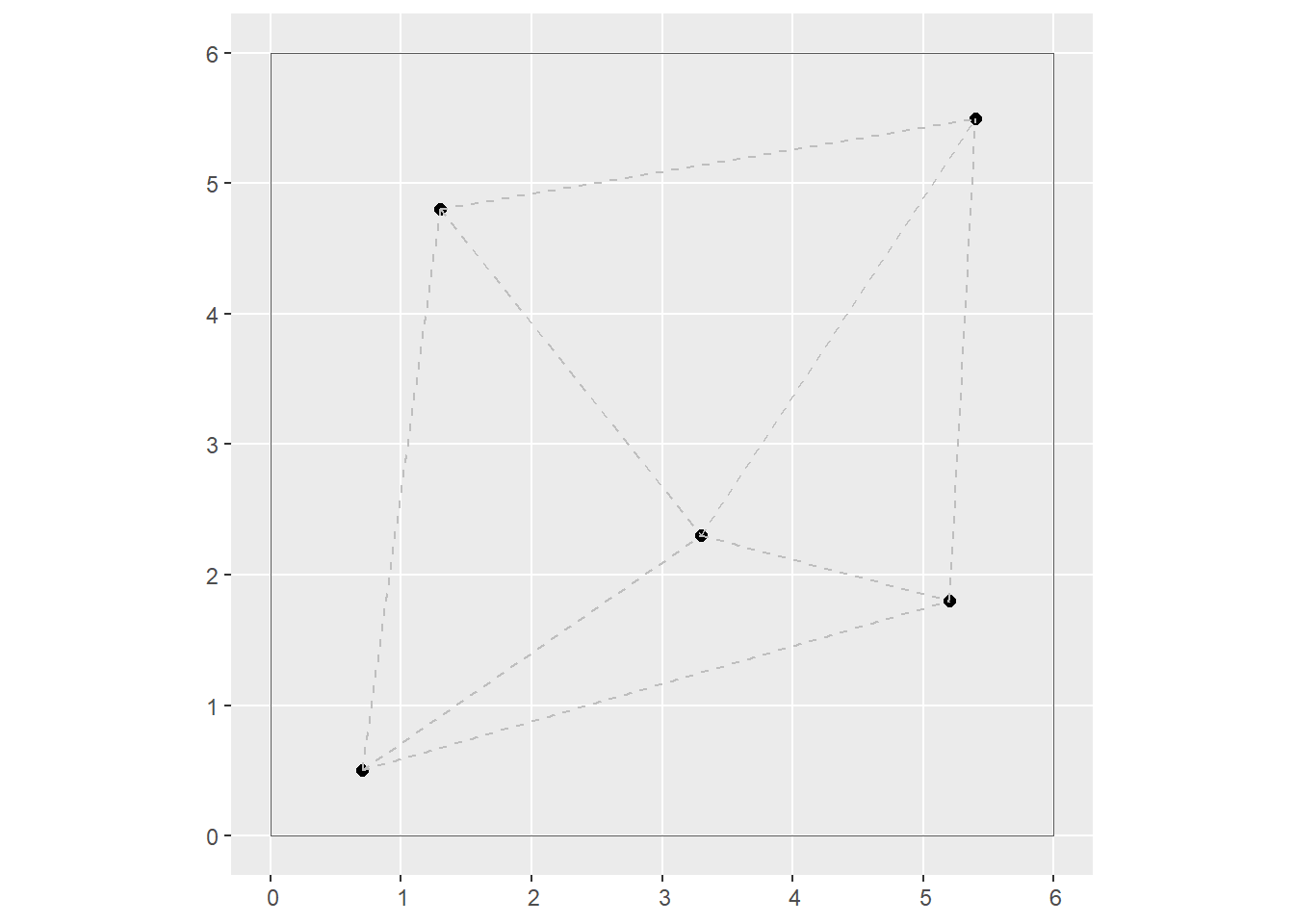
Notice that the plot above is already a tessellation, with the points at the vertices of the triangles.
- The perpendicular bisectors of each triangle are found and extended, until they intersect. The resulting tessellation is a set of Voronoi polygons:
# The function `st_voronoi()` from the `sf` package is used
# to create Voronoi polygons based on points
vor <- st_voronoi(uv_coords)
ggplot(data = uv_coords) +
geom_sf(size = 2) +
geom_sf(data = l2n,
color = "gray",
linetype = "dashed") +
geom_sf(data = vor,
fill = NA) +
coord_sf(xlim = c(0, 6),
y = c(0, 6))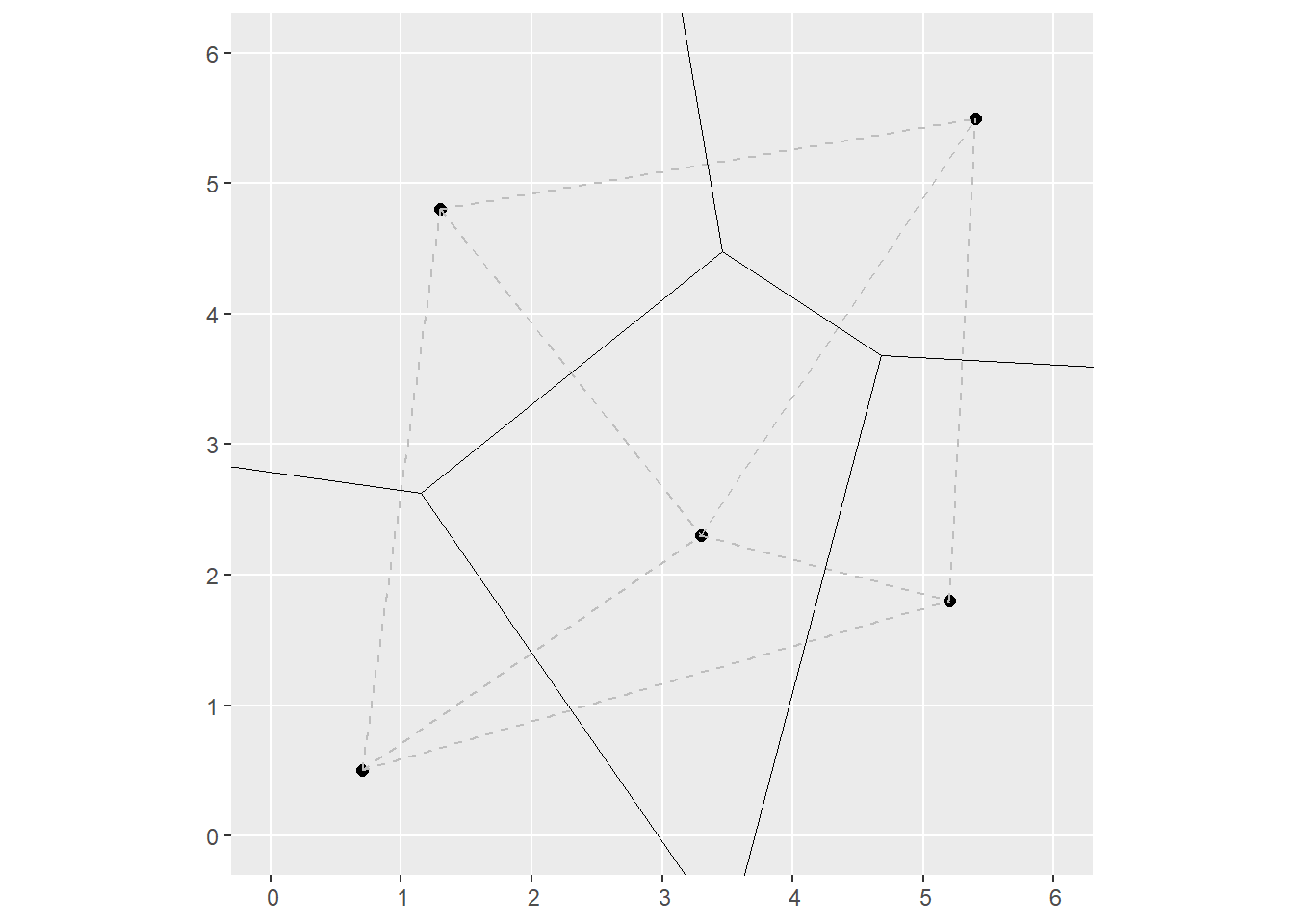
The triangulation was used to generate a second tessellation, i.e., the Voronoi polygons. These polygons have the property that any point \(p_i\) inside the polygon with generating point \(p_g\) in it, is closer to \(p_g\) than to any other generating point \(p_k\) on the plane. For this reason, Voronoi polygons are used to obtain areas of influence, among other applications.
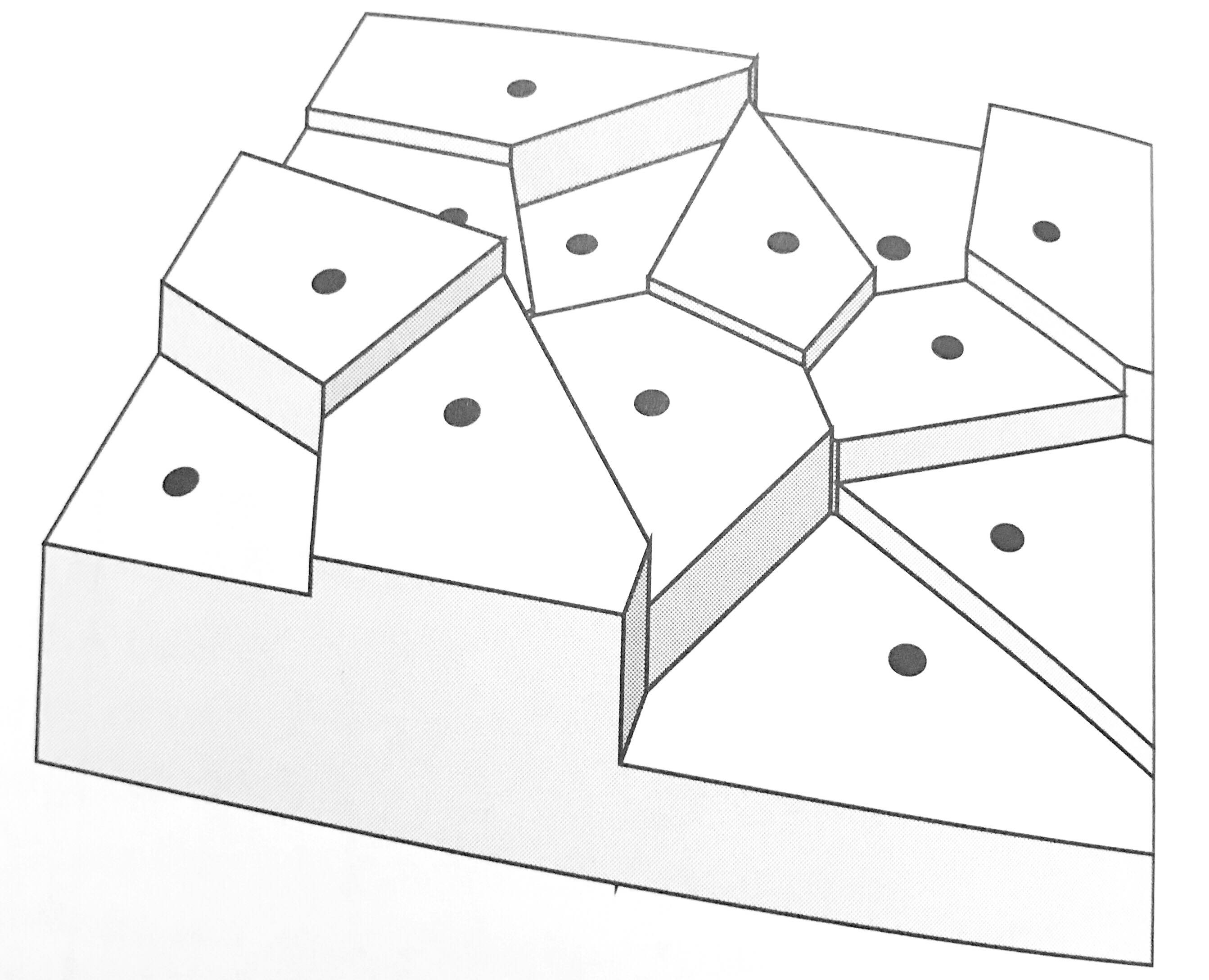
There are other ways of obtaining Voronoi polygons, as Figure 1 below illustrates. Voronoi polygons in the figure are created by radial growth. The basic concept is the same, but implemented in a different way: find every point that is closest to \(p_g\). When two circles touch, they become the boundary between all points that are closer to \(p_g\) and \(p_k\) respectively. Continue growing until the plane is fully covered.
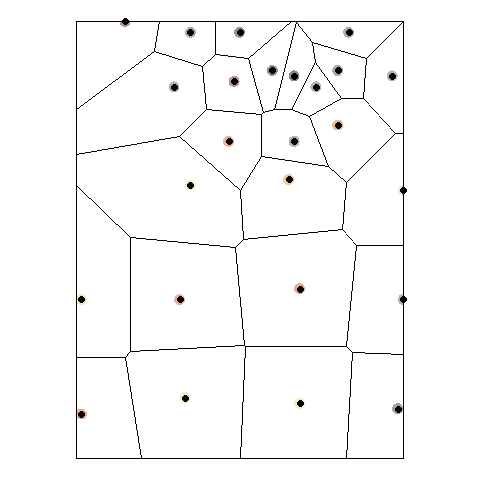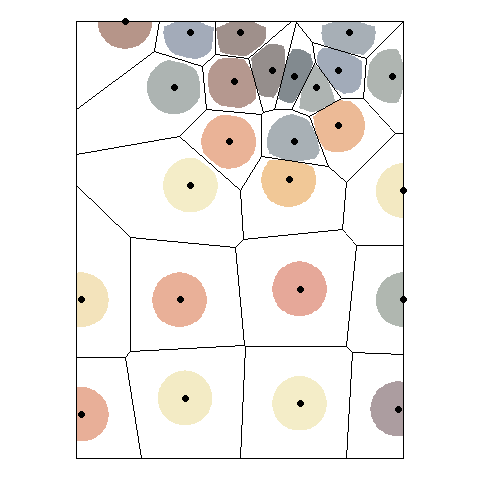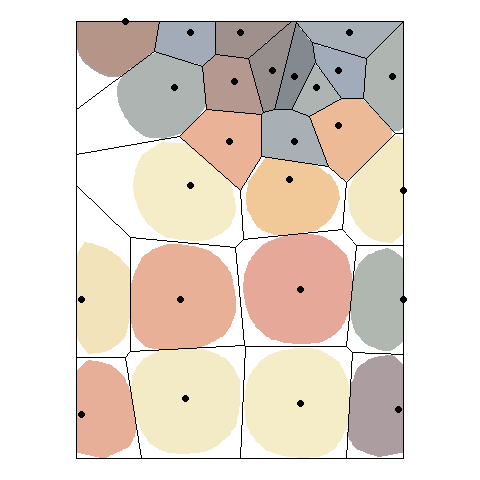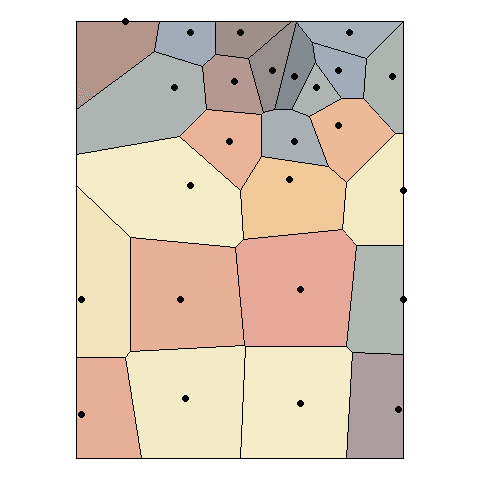
The Voronoi polygons for the sample data set can be obtained in R as follows.
First, we will convert the Walker_Lake dataframe to a simple features object using as follows:
# Function `st_as_sf()` takes a foreign object
# (foreign to the `sf` package) and converts it
# into a simple features object. If the foreign
# object is points, the coordinates can be named
# by means of the argument `coords`.
Walker_Lake.sf <- Walker_Lake |>
st_as_sf(coords = c("X", "Y"))Once we have an sf object of the points, the geometry can be used to create the Voronoi polygons:
# The function `do.call(what, arg)` applies a function
# `what` to the argument `arg`. In this case, we extract
# the geometry of the `sf` object (i.e., the coordinates
# of the points) and apply the function `c()` to concatenate
# the coordinates to obtain a MULTIPOINT object.
# The pipe operator passes the MuLTIPOINT object to function `st_voronoi()`
vpolygons <- do.call(c, st_geometry(Walker_Lake.sf)) |>
st_voronoi() |>
# The output of `st_voronoi()` is a collection of geometries,
# which we pass to the following function for extraction.
st_collection_extract()After the step above we already have the Voronoi polygons:
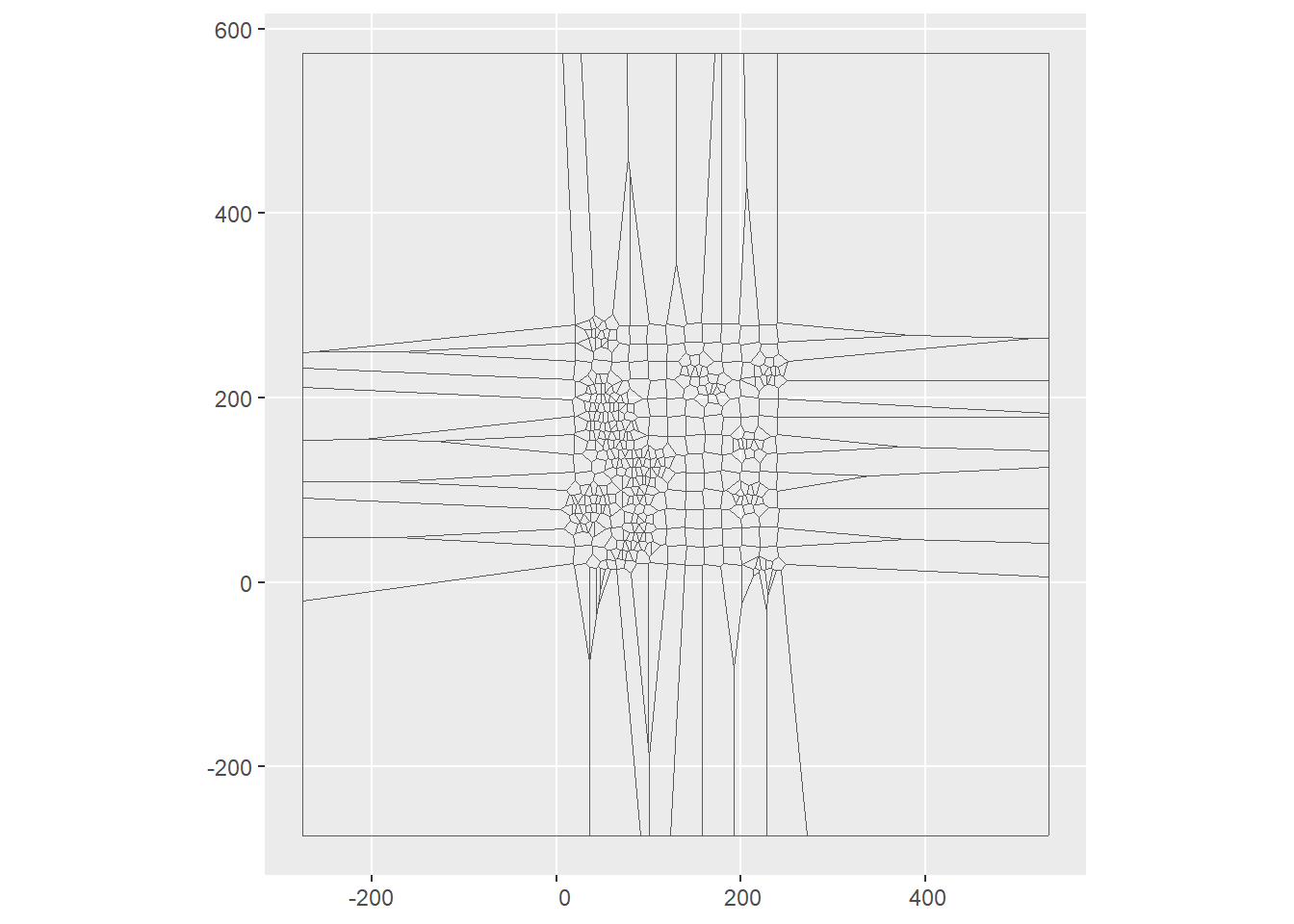
However, these polygons are just the geometry and lack other attributes that we originally had for the points. See:
## Geometry set for 6 features
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: -275 ymin: -19.79545 xmax: 39.35 ymax: 232.9318
## CRS: NA
## First 5 geometries:## POLYGON ((-275 109.5, -180.5 109.5, 10.8913 99....## POLYGON ((-275 91.88636, 4.207317 79.19512, 14....## POLYGON ((-275 49, -171.5 49, 18.9248 38.42084,...## POLYGON ((20.40385 52.61538, 18.36567 50.35075,...## POLYGON ((18.36567 50.35075, 20.40385 52.61538,...For this reason, we need to join the Voronoi polygons to the attributes of the points. To do this, we will first copy the sf object with the original points to a new dataframe, and then replace the geometry of the points with the geometry of the polygons:
Walker_Lake.v <- Walker_Lake.sf
Walker_Lake.v$geometry <- vpolygons[unlist(st_intersects(Walker_Lake.sf, vpolygons))] The new Walker_Lake.v object now includes the attributes of the original points as well as the geometry of the polygons:
## Simple feature collection with 6 features and 4 fields
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: -275 ymin: -275 xmax: 35.5 ymax: 120
## CRS: NA
## # A tibble: 6 × 5
## ID V U T geometry
## <chr> <dbl> <dbl> <fct> <POLYGON>
## 1 1 0 NA 2 ((-275 -275, -275 -19.79545, 18.05556 20.16667, 19.59…
## 2 2 0 NA 2 ((-275 49, -171.5 49, 18.9248 38.42084, 18.05556 20.1…
## 3 3 224. NA 2 ((-171.5 49, 8.1875 57.98438, 18.36567 50.35075, 20.0…
## 4 4 434. NA 2 ((-275 91.88636, 4.207317 79.19512, 14.18919 72.54054…
## 5 5 412. NA 2 ((-275 109.5, -180.5 109.5, 10.8913 99.93043, 14.2857…
## 6 6 587. NA 2 ((-180.5 109.5, 19 120, 20 119.1, 20 109.95, 10.8913 …We can now plot the attributes as the polygons. The value of \(z\) for a tile is the same as the value of the variable for its corresponding generating point, or \(z_{p_g}\). This is the plot for the current example:
ggplot(Walker_Lake.v) +
geom_sf(aes(fill = V)) +
scale_fill_distiller(palette = "OrRd",
direction = 1)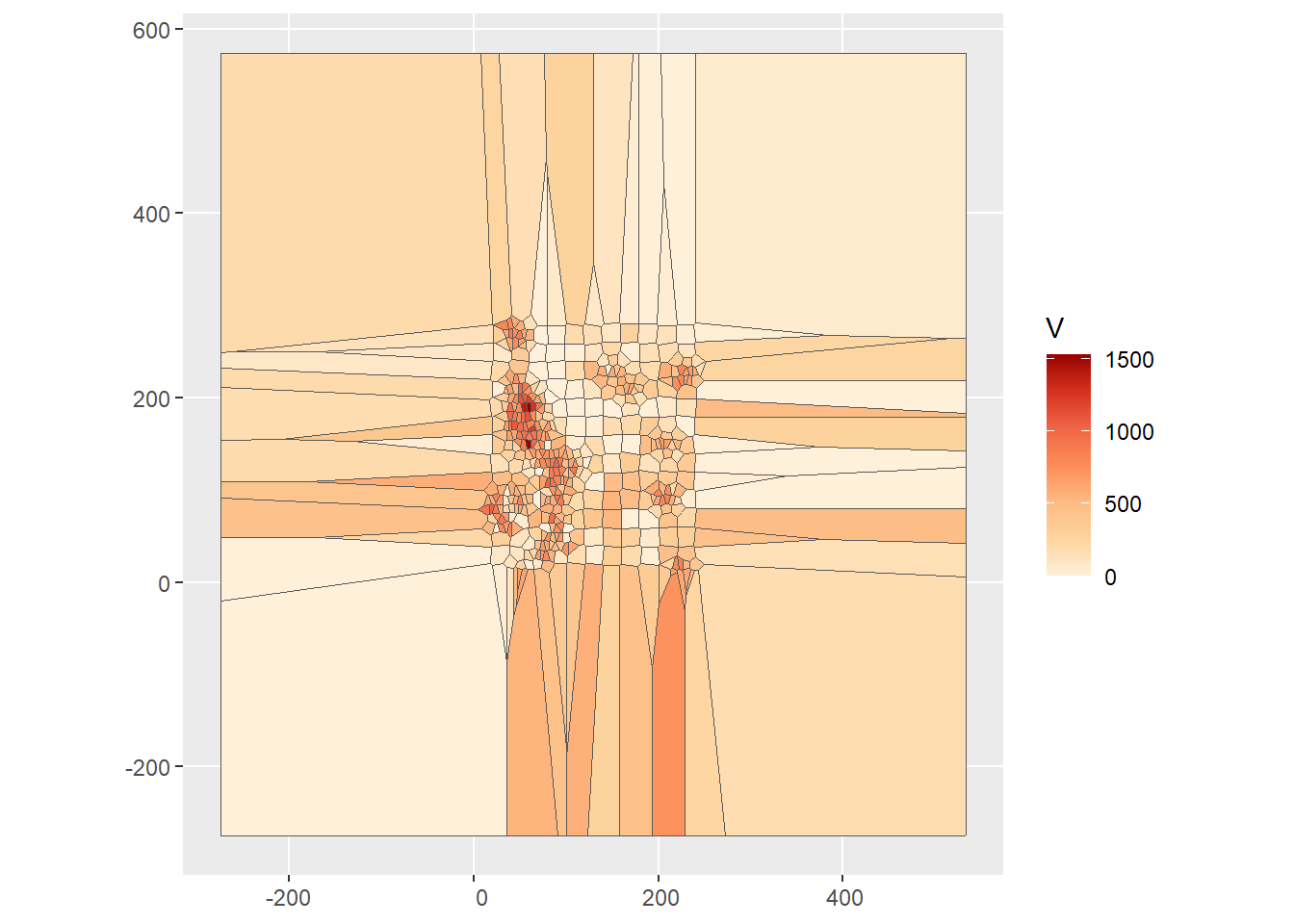
We can see that the Voronoi polygons extend well beyond the extent of the original points, and in the plot add a large amount of unnecessary area. We can improve the plot in two ways, by limiting the extent for plotting, or by clipping the polygons. Here we will try the latter, with a bounding box that covers the region of interest:
# Function `st_polygon()` creates an `sf` object with a
# polygon or polygons. In this case, we create a single
# polygon, a rectangle with corners given by the coordinates
# in the function.
W.bbox <- st_polygon(list(rbind(c(0,0),
c(259,0),
c(259, 299),
c(0, 299),
c(0,0))))The intersection of the polygons with the box clips the polygons:
## Warning: attribute variables are assumed to be spatially constant throughout
## all geometriesThis is the plot after fixing this issue:
ggplot(Walker_Lake.v) +
geom_sf(aes(fill = V)) +
geom_sf(data = Walker_Lake.sf,
size = 0.1) +
scale_fill_distiller(palette = "OrRd",
direction = 1)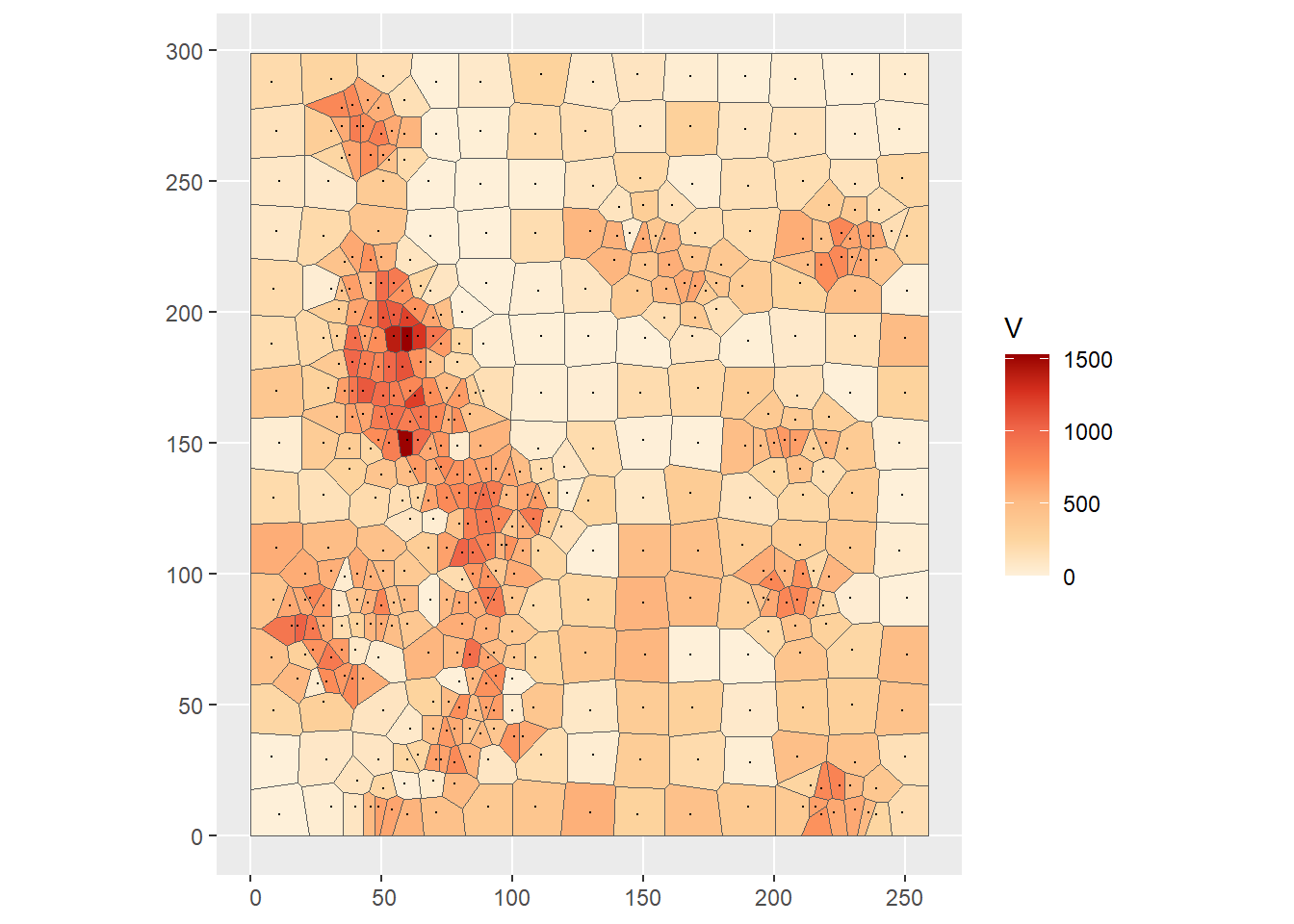
As you can see, the points in the sample have been converted to a surface from which the value of \(z\) can be estimated at any point as desired, from the value of \(z\) of the closest point used to generate the tiles. This can be expressed as follows: \[ \hat{z}_p = z_{p_g}\text{ for } p_g\text{ with } d_{pp_g}<d_{pp_k}\forall{k} \]
31.7 Inverse distance weighting (IDW)
The tile-based approach above assumes that the field is flat within each polygon (see Figure 2). This is in most cases an unrealistic assumption. Other approaches to interpolate a spatial variable allow the estimated value of \(z_p\) to vary with proximity to observations. Such is the case of IDW.
Inverse distance weighting takes the following form: \[ \hat{z}_p = \frac{\sum_{i=1}^n{w_{pi}z_i}}{\sum_{i=1}^n{w_{pi}}} \]
This will probably look familiar to you, because it is formally identical to the spatial moving average. The difference is in how the “spatial weights” \(w_{pi}\) are defined. For IDW, the spatial weights are given by a function of the inverse power of distance, as follows: \[ w_{pi} = \frac{1}{d_{pi}^\gamma} \] In the expression above, parameter \(\gamma\) controls the steepness of the decay function, with smaller values giving greater weight to more distant locations. Large values of \(\gamma\) converge to a 1-point average (so that the interpolated value is identical to the nearest observation; you can verify this).
We can see that inverse distance weighting is a weighted average of all observations in the sample, but with greater weight given to more proximate observations. This approach is implemented in R in the package spatstat with the function idw. To use this function, the points must be converted into a ppp object. This necessitates that we define a window object, which we do based on the bounding box that we created for the Voronoi polygons:
# Function `as.owin()` takes the polygon with the bounding box
# we created above and converts it into an `owin` object for
# use with the `spatstat` package.
W.owin <- as.owin(W.bbox)
# We can create a `ppp` object with the coordinates of the points
Walker_Lake.ppp <- as.ppp(X = Walker_Lake[,2:4], W = W.owin)The call to the function requires a ppp object and the argument for the power to use in the inverse distance function. In this call, the power is set to 1:
The value (output) of this function is an im object. Objects of this type are used by the package spatstat to work with raster data. It can be simply plotted as follows:
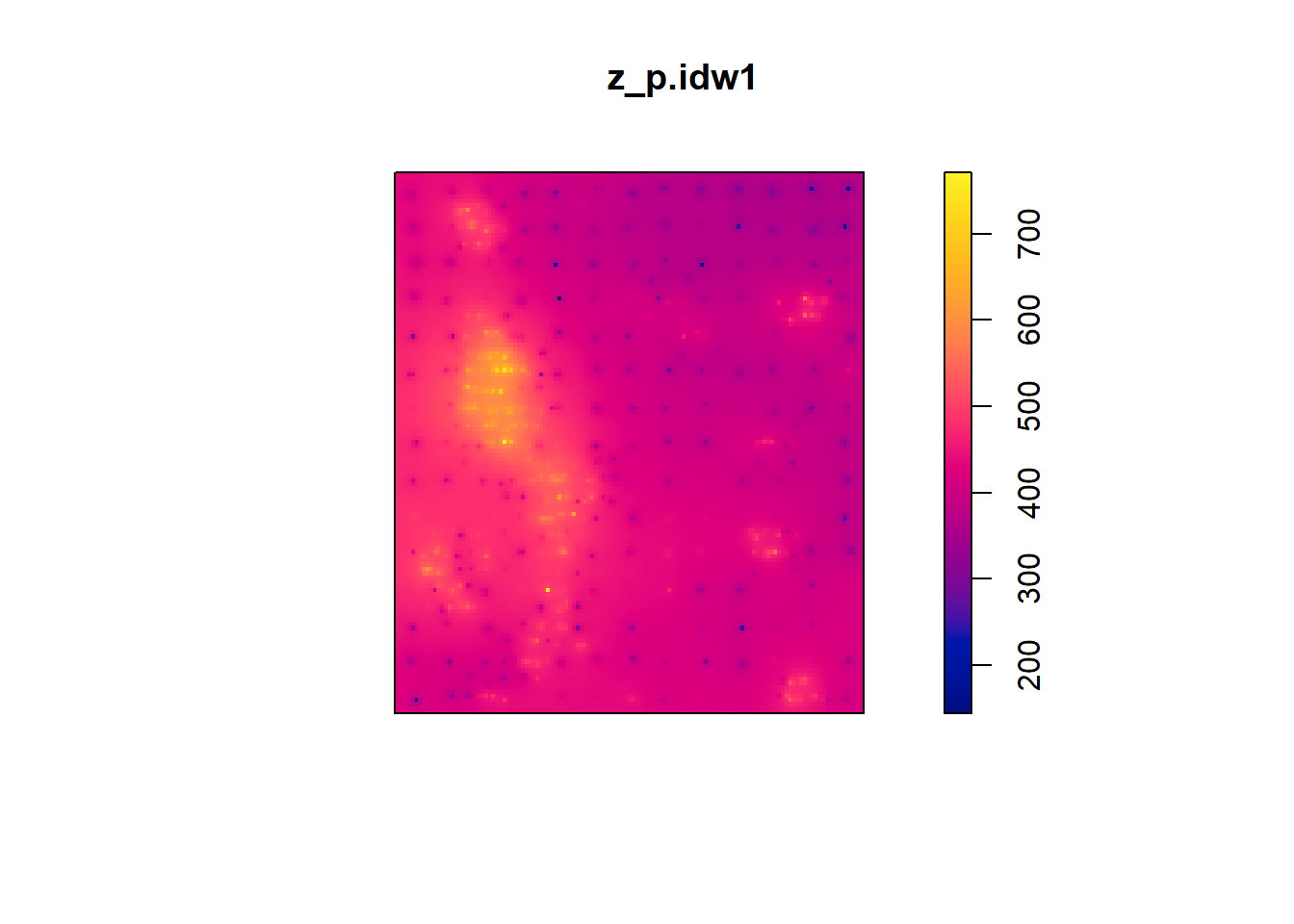
Or the information can be extracted for greater control of the aspect of the plot in ggplot2:
data.frame(expand.grid(X= z_p.idw1$xcol,
Y = z_p.idw1$yrow),
# transpose matrix
V = as.vector(t(z_p.idw1$v))) |>
ggplot(aes(x = X,
y = Y,
fill = V)) +
geom_tile() +
scale_fill_distiller(palette = "OrRd",
direction = 1) +
coord_equal()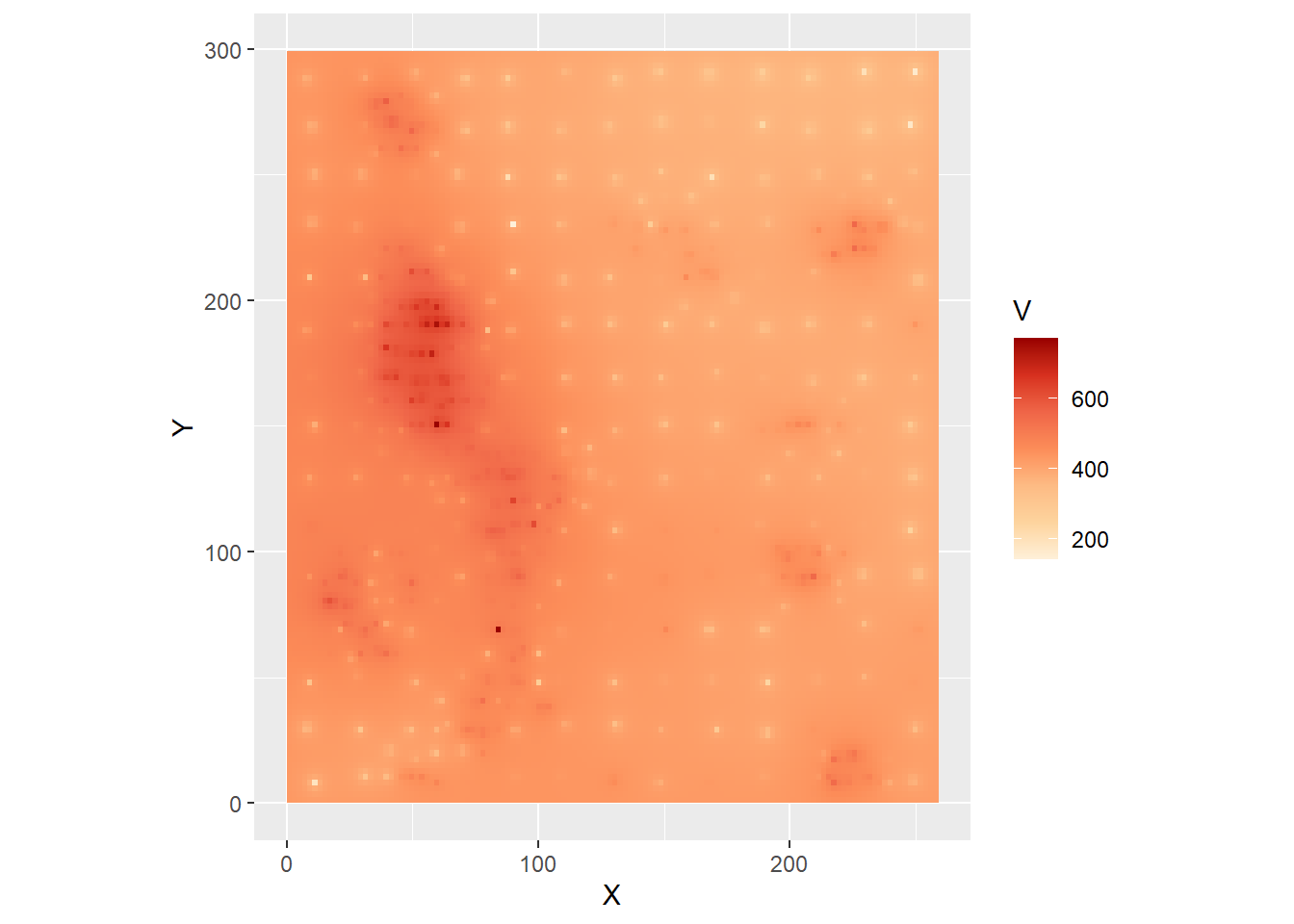
Notice the dots where the observations are - the value of the field is known there. We can explore the effect of changing the parameter for the power, by using \(\gamma = 0.5, 1, 2, \text{ and } 5\):
#Inverse distance weighting for Walker Lake
# using three different gamma variables
z_p.idw05 <- idw(Walker_Lake.ppp, power = 0.5)
z_p.idw2 <- idw(Walker_Lake.ppp, power = 2)
z_p.idw5 <- idw(Walker_Lake.ppp, power = 5)For ease of comparison, we will collect the information into a single data frame:
z_p.idw05.df <- data.frame(expand.grid(X = z_p.idw05$xcol,
Y = z_p.idw05$yrow),
V = as.vector(t(z_p.idw05$v)),
Power = "P05")
z_p.idw1.df <- data.frame(expand.grid(X= z_p.idw1$xcol,
Y = z_p.idw1$yrow),
V = as.vector(t(z_p.idw1$v)),
Power = "P1")
z_p.idw2.df <- data.frame(expand.grid(X= z_p.idw2$xcol,
Y = z_p.idw2$yrow),
V = as.vector(t(z_p.idw2$v)),
Power = "P2")
z_p.idw5.df <- data.frame(expand.grid(X= z_p.idw5$xcol,
Y = z_p.idw5$yrow),
V = as.vector(t(z_p.idw5$v)),
Power = "P5")
# Bind the data frames
idw_df <- rbind(z_p.idw05.df,
z_p.idw1.df,
z_p.idw2.df,
z_p.idw5.df)We can now plot using the facet_wrap function to compare the results side by side:
ggplot(data = idw_df,
aes(x = X,
y = Y,
fill = V)) +
geom_tile() +
scale_fill_distiller(palette = "OrRd",
direction = 1) +
coord_equal() +
facet_wrap(~ Power,
ncol = 2)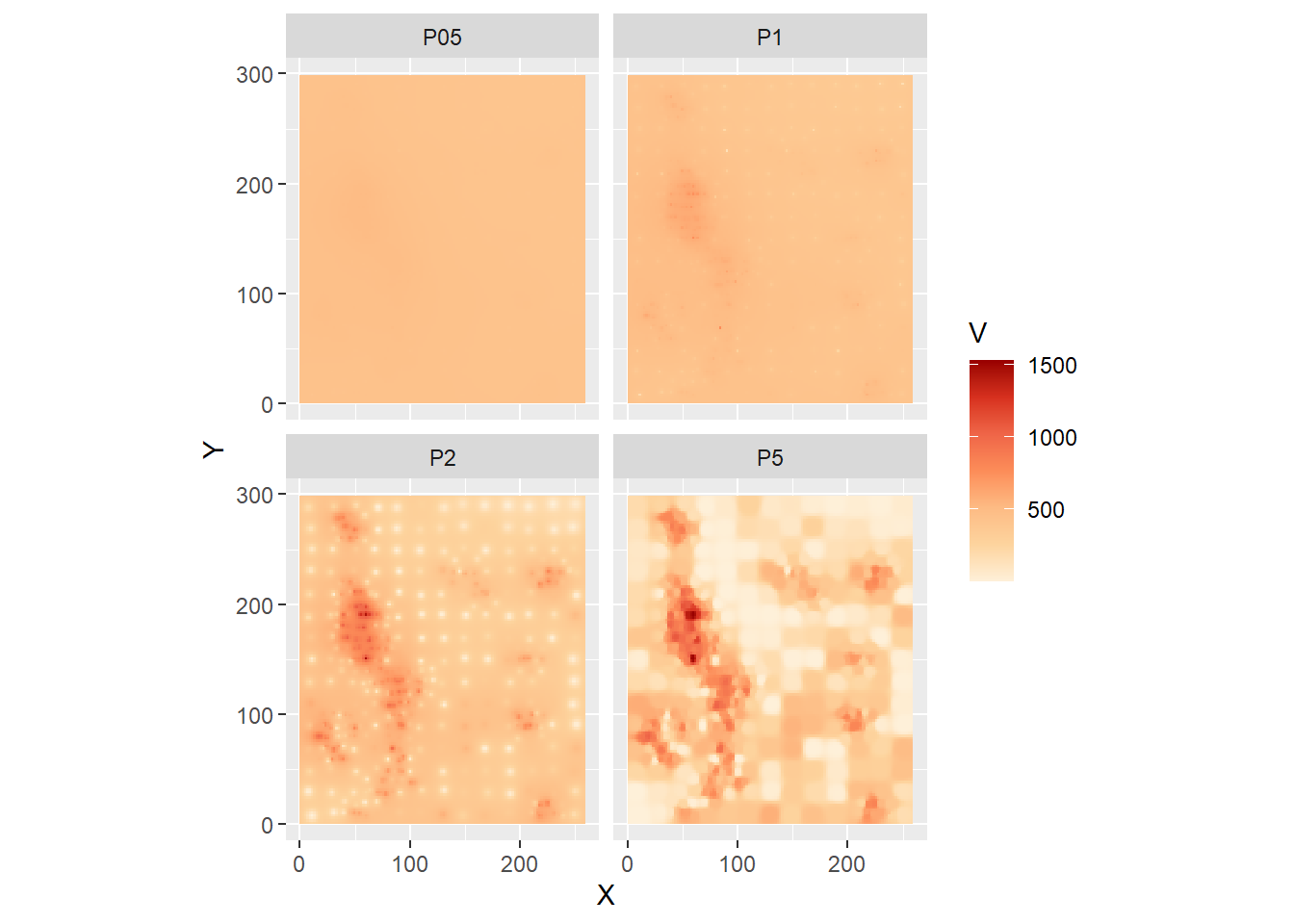
Notice how smaller values of \(\gamma\) “flatten” the predictions, in the extreme tending towards to global average, as all observations are weighted equally. Larger values, on the other hand, tend to be the average of a single point, the closest one. In fact, this replicates the Voronoi polygons, as seen in the following plot that combines the Voronoi polygons (without filling!) and the predictions from the IDW algorithm with \(\gamma = 5\):
ggplot() +
geom_tile(data = subset(idw_df,
Power = "P5"),
aes(x = X,
y = Y,
fill = V)) +
geom_sf(data = Walker_Lake.v,
color = "white",
fill = NA) +
scale_fill_distiller(palette = "OrRd",
direction = 1)## Warning: In subset.data.frame(idw_df, Power = "P5") :
## extra argument 'Power' will be disregarded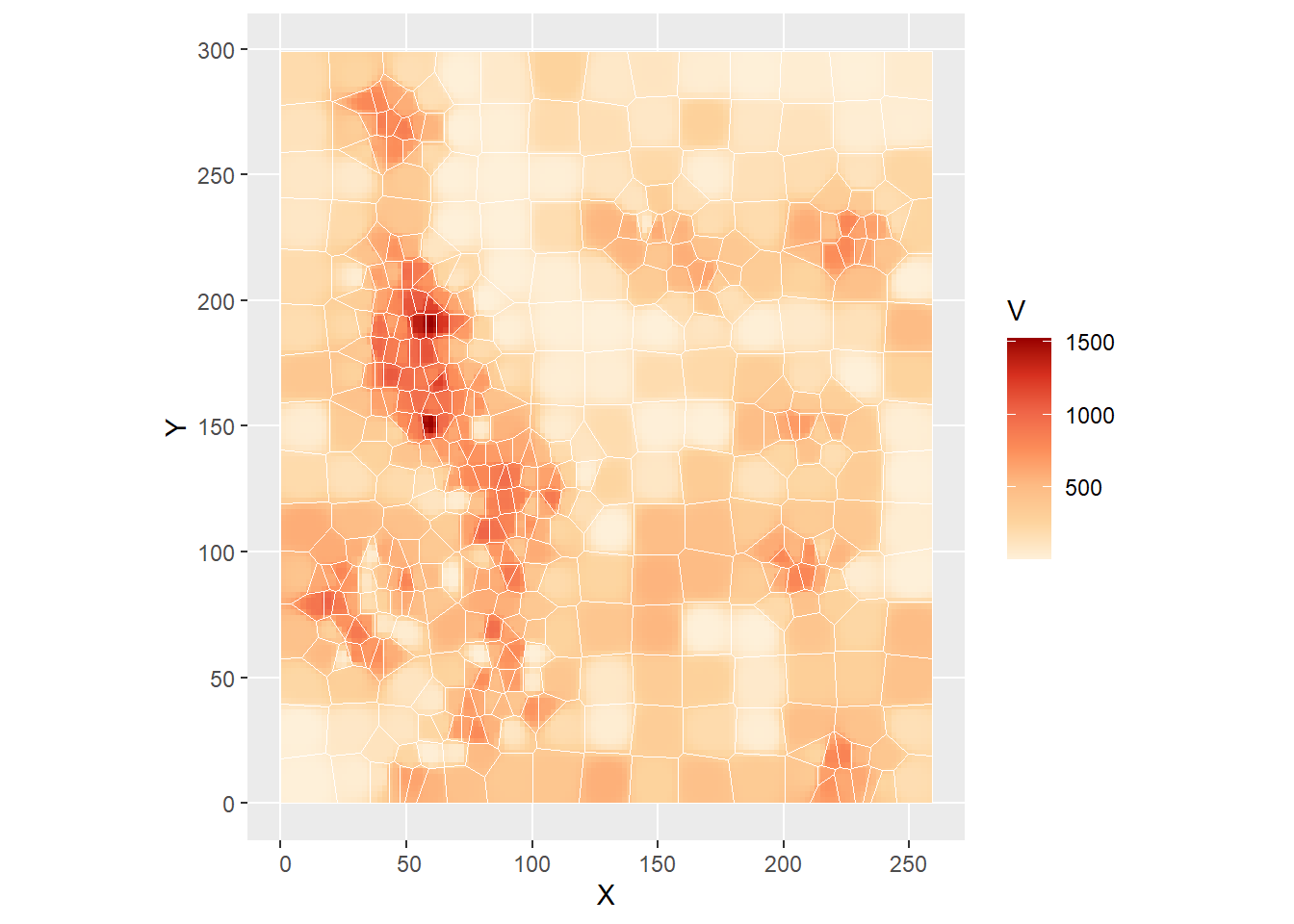
Clearly, selection of a value for \(\gamma\) is an important modeling decision when using IDW.
31.8 \(k\)-point means
Another interpolation technique that is based on the idea of moving averages is \(k\)-point means. Again, this will look familiar to you, because it is also formally identical to the spatial moving average: \[ \hat{z}_p = \frac{\sum_{i=1}^n{w_{pi}z_i}}{\sum_{i=1}^n{w_{pi}}} \]
The spatial weights in this case, however, are defined in terms of \(k\)-nearest neighbors: \[ w_{pi} = \bigg\{\begin{array}{ll} 1 & \text{if } i \text{ is one of } k \text{th nearest neighbors of } p \text{ for a given }k \\ 0 & otherwise \\ \end{array} \]
Clearly, the above becomes: \[ \hat{z}_p = \sum_{i=1}^n {w_{pi}^{st}z_i} \]
If row-standardized spatial weights are used.
We can calculate \(k\)-point means using the example. For this, we need to define a set of “target” coordinates, that is, the points where we wish to interpolate, which we also convert to simple features:
# Create a fine grid for prediction, i.e., our "target"
# points
target_xy <- expand.grid(x = seq(0.5,
259.5,
2.2),
y = seq(0.5,
299.5,
2.2)) |>
st_as_sf(coords = c("x", "y"))The inputs to the function are a simple features object with the variable that we wish to interpolate, a simple features object with the point to which we wish to interpolate, the name of the variable to interpolate (which must be in the source table), and the number of points to use for interpolations (see below). The value (output) of the function is a simple features table with the target points, as well as estimated values of \(\hat{z_p}\) at those points. Using the three nearest neighbors:
# Use the source and target points to interpolate
kpoint.3 <- kpointmean(source_xy = Walker_Lake.sf,
target_xy = target_xy,
z = V,
k = 3) |>
# Rename the columns to match the names of columns in
# our other data frame
rename(V = z)## projected pointsWe can plot the interpolated field now:
ggplot() +
geom_sf(data = kpoint.3,
aes(color = V)) +
scale_color_distiller(palette = "OrRd",
direction = 1)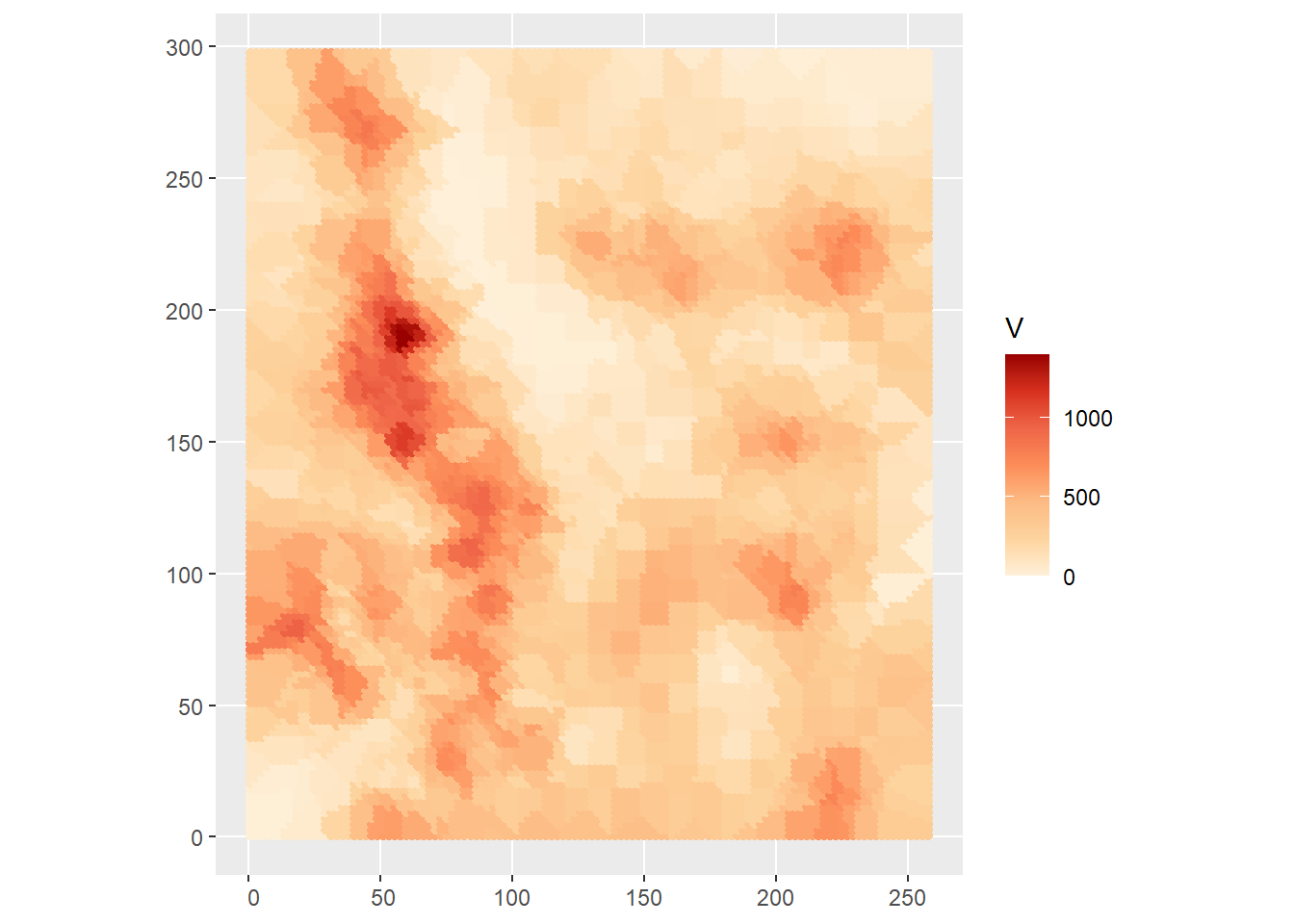
As with other spatially moving averages, the crucial aspect of implementing \(k\)-point means is the selection of \(k\). A large value will tend towards the global average, whereas a value of 1 will tend to replicate the Voronoi polygons (see below):
# Calculate k-point means using only one point. Rename the variables to match
kpoint.1 <- kpointmean(source_xy = Walker_Lake.sf,
target_xy = target_xy,
z = V,
k = 1) |>
# Rename the columns to match the names of columns in
# our other data frame
rename(V = z)## projected pointsThis is the plot with the Voronoi polygons:
# Plot and overlay the Voronoi polygons
ggplot() +
geom_sf(data = kpoint.1,
aes(color = V)) +
geom_sf(data = Walker_Lake.v,
color = "white", fill = NA) +
scale_color_distiller(palette = "OrRd",
direction = 1)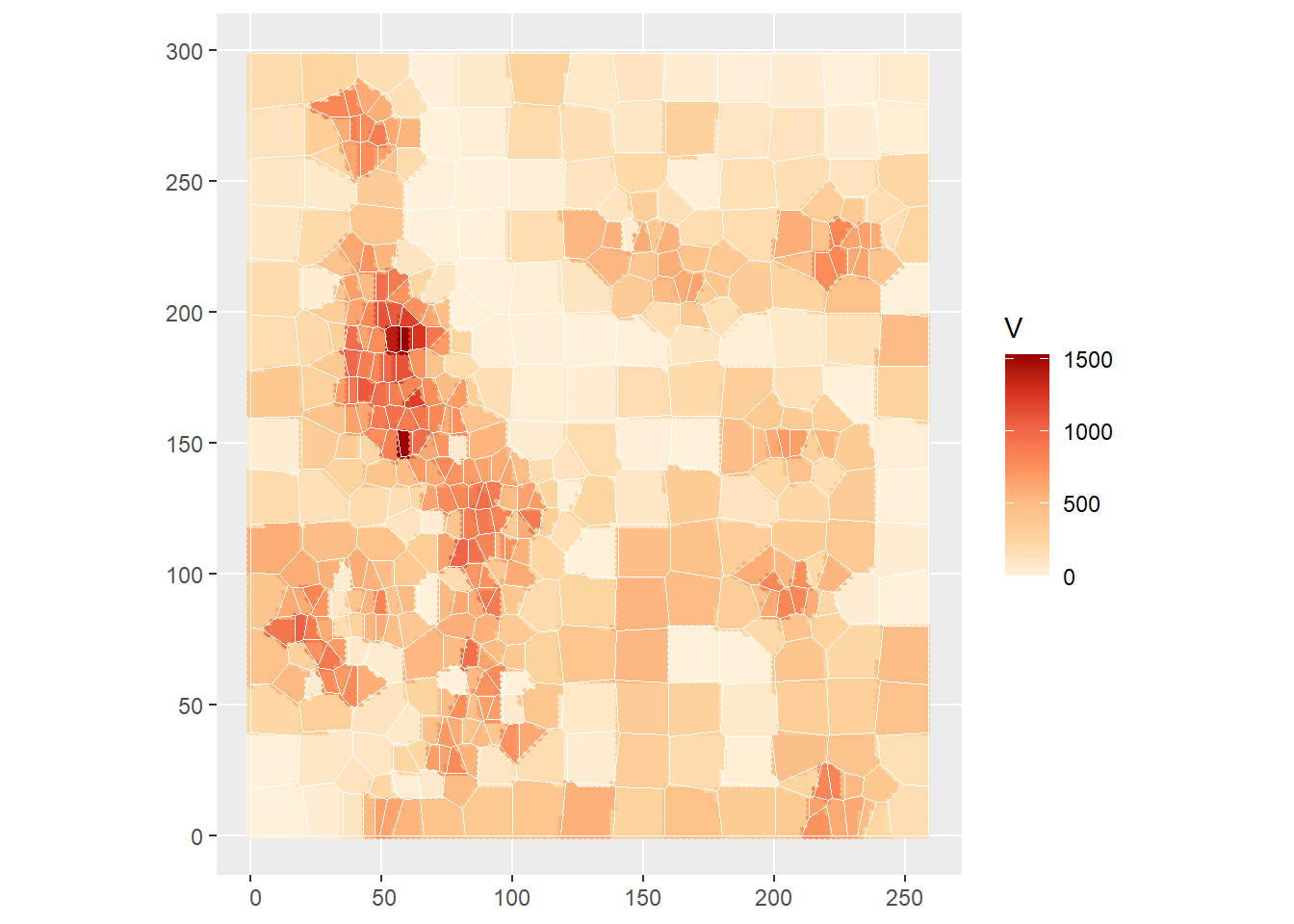
This shows that Voronoi polygons can be seen as a special case of IDW or \(k\)-point means depending on the way these two techniques are implemented.