Chapter 19 Area Data I
NOTE: The source files for this book are available with companion package {isdas}. The source files are in Rmarkdown format and packed as templates. These files allow you execute code within the notebook, so that you can work interactively with the notes.
19.1 Learning Objectives
In last few practices/sessions, you learned about spatial point patterns. The next few sessions will concentrate on area data.
In this practice, you will learn:
- A formal definition of area data.
- Processes and area data.
- Visualizing area data: Choropleth maps.
- Visualizing area data: Cartograms.
19.2 Suggested Readings
- Bailey TC and Gatrell AC (1995) Interactive Spatial Data Analysis, Chapter 7. Longman: Essex.
- Bivand RS, Pebesma E, and Gomez-Rubio V (2008) Applied Spatial Data Analysis with R, Chapter 9. Springer: New York.
- Brunsdon C and Comber L (2015) An Introduction to R for Spatial Analysis and Mapping, Chapter 7. Sage: Los Angeles.
- O’Sullivan D and Unwin D (2010) Geographic Information Analysis, 2nd Edition, Chapter 7. John Wiley & Sons: New Jersey.
19.3 Preliminaries
As usual, it is good practice to begin with a clean session to make sure that you do not have extraneous items there when you begin your work. The best practice is to restart the R session, which can be accomplished for example with command/ctrl + shift + F10. An alternative to only purge user-created objects from memory is to use the R command rm (for “remove”), followed by a list of items to be removed. To clear the workspace from all objects, do the following:
Note that ls() lists all objects currently on the workspace.
Load the libraries you will use in this activity:
library(cartogram) # Create Cartograms with R
library(isdas) # Companion Package for Book An Introduction to Spatial Data Analysis and Statistics
library(gridExtra) # Miscellaneous Functions for "Grid" Graphics
library(plotly) # Create Interactive Web Graphics via 'plotly.js'
library(sf) # Simple Features for R
library(tidyverse) # Easily Install and Load the 'Tidyverse'Read the data used in this chapter.
The data are an object of class sf that includes the spatial information for the census tracts in the Hamilton Census Metropolitan Area in Canada and a series of demographic variables from the 2011 Census of Canada.
You can quickly verify the contents of the dataframe by means of summary:
## ID AREA TRACT POPULATION
## Min. : 919807 Min. : 0.3154 Length:188 Min. : 5
## 1st Qu.: 927964 1st Qu.: 0.8552 Class :character 1st Qu.: 2639
## Median : 948130 Median : 1.4157 Mode :character Median : 3595
## Mean : 948710 Mean : 7.4578 Mean : 3835
## 3rd Qu.: 959722 3rd Qu.: 2.7775 3rd Qu.: 4692
## Max. :1115750 Max. :138.4466 Max. :11675
## POP_DENSITY AGE_LESS_20 AGE_20_TO_24 AGE_25_TO_29
## Min. : 2.591 Min. : 0.0 Min. : 0.0 Min. : 0.0
## 1st Qu.: 1438.007 1st Qu.: 528.8 1st Qu.:168.8 1st Qu.:135.0
## Median : 2689.737 Median : 750.0 Median :225.0 Median :215.0
## Mean : 2853.078 Mean : 899.3 Mean :253.9 Mean :232.8
## 3rd Qu.: 3783.889 3rd Qu.:1110.0 3rd Qu.:311.2 3rd Qu.:296.2
## Max. :14234.286 Max. :3285.0 Max. :835.0 Max. :915.0
## AGE_30_TO_34 AGE_35_TO_39 AGE_40_TO_44 AGE_45_TO_49
## Min. : 0.0 Min. : 0.0 Min. : 0.0 Min. : 0.0
## 1st Qu.: 135.0 1st Qu.: 145.0 1st Qu.: 170.0 1st Qu.:203.8
## Median : 195.0 Median : 200.0 Median : 230.0 Median :282.5
## Mean : 228.2 Mean : 239.6 Mean : 268.7 Mean :310.6
## 3rd Qu.: 281.2 3rd Qu.: 280.0 3rd Qu.: 325.0 3rd Qu.:385.0
## Max. :1320.0 Max. :1200.0 Max. :1105.0 Max. :880.0
## AGE_50_TO_54 AGE_55_TO_59 AGE_60_TO_64 AGE_65_TO_69 AGE_70_TO_74
## Min. : 0.0 Min. : 0.0 Min. : 0 Min. : 0.0 Min. : 0.0
## 1st Qu.:203.8 1st Qu.:175.0 1st Qu.:140 1st Qu.:115.0 1st Qu.: 90.0
## Median :280.0 Median :240.0 Median :220 Median :157.5 Median :130.0
## Mean :300.3 Mean :257.7 Mean :229 Mean :174.2 Mean :139.7
## 3rd Qu.:375.0 3rd Qu.:325.0 3rd Qu.:295 3rd Qu.:221.2 3rd Qu.:180.0
## Max. :740.0 Max. :625.0 Max. :540 Max. :625.0 Max. :540.0
## AGE_75_TO_79 AGE_80_TO_84 AGE_MORE_85 geometry
## Min. : 0.00 Min. : 0.00 Min. : 0.00 POLYGON :188
## 1st Qu.: 68.75 1st Qu.: 50.00 1st Qu.: 35.00 epsg:26917 : 0
## Median :100.00 Median : 77.50 Median : 70.00 +proj=utm ...: 0
## Mean :118.32 Mean : 95.05 Mean : 87.71
## 3rd Qu.:160.00 3rd Qu.:120.00 3rd Qu.:105.00
## Max. :575.00 Max. :420.00 Max. :400.0019.4 Area Data
Every phenomena can be measured at a location (ask yourself, what exists outside of space?).
In point pattern analysis, the unit of support is the point, and the source of randomness is the location itself. Many other forms of data are also collected at points. For instance, when the census collects information on population, at its most basic, the information can be georeferenced to an address, that is, a point.
In numerous applications, however, data are not reported at their fundamental unit of support, but rather are aggregated to some other geometry, for instance an area. This is done for several reasons, including the privacy and confidentiality of the data. Instead of reporting individual-level information, the information is reported for zoning systems that often are devised without consideration to any underlying social, natural, or economic processes.
Census data, for example, are reported at different levels of geography. In Canada, the smallest publicly available geography is called a Dissemination Area or DA. A DA in Canada contains a population between 400 and 700 persons. Thus, instead of reporting that one person (or more) are located at a point (i.e., an address), the census reports the population for the DA. Other data are aggregated in similar ways (income, residential status, etc.)
At the highest level of aggregation, national level statistics are reported, such as Gross Domestic Product, or GDP. Economic production is not evenly distributed across space; however, the national GDP does not distinguish regional variations in this process.
Ideally, a data analyst would work with data in its most fundamental support. This is not always possible, and therefore many techniques have been developed to work with data that have been aggregated to zones.
When working with areas, it is less practical to identify the area with the coordinates (as we did with points). After all, areas will be composed of lines and reporting all the relevant coordinates is impractical. Sometimes the geometric centroids of the areas are used instead.
More commonly, areas are assigned an index or unique identifier, so that a region will typically consist of a set of \(n\) areas as follows: \[ R = A_1 \cup A_2 \cup A_3 \cup ...\cup A_n. \]
The above is read as “the Region R is the union of Areas 1 to n”.
Regions can have a set of \(k\) attributes or variables associated with them, for instance: \[ \textbf{X}_i=[x_{i1}, x_{i2}, x_{i3},...,x_{ik}] \]
These attributes will typically be counts (e.g., number of people in a DA), or some summary measure of the underlying data (e.g., mean commute time).
19.5 Processes and Area Data
Imagine that data on income by household were collected as follows:
# Here, we are creating a dataframe with three columns, coordinates x and y in space to indicate the locations of households, and their income.
df <- data.frame(x = c(0.3, 0.4, 0.5, 0.6, 0.7), y = c(0.1, 0.4, 0.2, 0.5, 0.3), Income = c(30000, 30000, 100000, 100000, 100000))Households are geocoded as points with coordinates x and y, whereas income is in dollars.
Plot the income as points (hover over the points to see the attributes):
# The `ggplot()` function is used to create a plot. The function `geom_point()` adds points to the plot, using the values of coordinates x and y, and coloring by Income. Higher income households appear to be on the East regions of the area.
p <- ggplot(data = df, aes(x = x, y = y, color = Income)) +
geom_point(shape = 17, size = 5) +
coord_fixed()
ggplotly(p)The underlying process is one of income sorting, with lower incomes to the west, and higher incomes to the east. This could be due to a geographical feature of the landscape (for instance, an escarpment), or the distribution of the housing stock (with a neighborhood that has more expensive houses). These are examples of a variable that responds to a common environmental factor. As an alternative, people may display a preference towards being near others that are similar to them (this is called homophily). When this happens, the variable responds to itself in space.
The quality of similarity or dissimilarity between neighboring observations of the same variable in space is called spatial autocorrelation. You will learn more about this later on.
Another reason why variables reported for areas could display similarities in space is as an consequence of the zoning system.
Suppose for a moment that the data above can only be reported at the zonal level, perhaps because of privacy and confidentiality concerns. Thanks to the great talent of the designers of the zoning system (or a felicitous coincidence!), the zoning system is such that it is consistent with the underlying process of sorting. The zones, therefore, are as follows:
# Here, we create a new dataframe with the coordinates necessary to define two zones. The zones are rectangles, so we need to define four corners for each. "Zone_ID" only has 2 values because there are only two zones in the analysis.
zones1 <- data.frame(x1=c(0.2, 0.45), x2=c(0.45, 0.80), y1=c(0.0, 0.0), y2=c(0.6, 0.6), Zone_ID = c('1','2'))If you add these zones to the plot:
# Similar to the plot above, but adding the zones with `geom_rect()` for plotting rectangles.
p <- ggplot() +
geom_rect(data = zones1, mapping = aes(xmin = x1, xmax = x2, ymin = y1, ymax = y2, fill = Zone_ID), alpha = 0.3) +
geom_point(data = df, aes(x = x, y = y, color = Income), shape = 17, size = 5) +
coord_fixed()
ggplotly(p)What is the mean income in zone 1? What is the mean income in zone 2? Not only are the summary measures of income highly representative of the observations they describe, the two zones are also highly distinct.
Imagine now that for whatever reason (lack of prior knowledge of the process, convenience for data collection, etc.) the zones instead are as follows:
# Note how the values have changed for x1 and x2. This reveals that the zones have shifted and are no longer the same as the plot above.
zones2 <- data.frame(x1=c(0.2, 0.55), x2=c(0.55, 0.80), y1=c(0.0, 0.0), y2=c(0.6, 0.6), Zone_ID = c('1','2'))If you plot these zones:
p <- ggplot() +
geom_rect(data = zones2, mapping = aes(xmin = x1, xmax = x2, ymin = y1, ymax = y2, fill = Zone_ID), alpha = 0.3) +
geom_point(data = df, aes(x = x, y = y, color = Income), shape = 17, size = 5) +
coord_fixed()
ggplotly(p)What is now the mean income of zone 1? What is the mean income of zone 2? The observations have not changed, and the generating spatial process remains the same. However, as you can see, the summary measures for the two zones are more similar in this case than they were when the zones more closely captured the underlying process.
19.6 Visualizing Area Data: Choropleth Maps
The very first step when working with spatial area data, perhaps, is to visualize the data.
Commonly, area data are visualized by means of choropleth maps. A choropleth map is a map of the polygons that form the areas in the region, each colored in a way to represent the value of an underlying variable.
Lets use ggplot2 to create a choropleth map of population in Hamilton. Notice that the fill color for the polygons is given by cutting the values of POPULATION in five equal segments. In other words, the colors represent zones in the bottom 20% of population, zones in the next 20%, and so on, so that the darkest zones are those with populations so large as to be in the top 20% of the population distribution:
# Geographical information can also be plotted using `ggplot2` when it is in the form of simple features or `sf`. Here, we create a plot with function `ggplot()`. We also have available the census tracts for Hamilton in an `sf` dataframe. To plot the distribution of the population in five equal segments (or quintiles), we apply the function `cut_number()` to the variable `POPULATION` from the `Hamilton_CT` census tract dataframe. The aesthetic value for `fill` will color the zones according to the population quintiles.
ggplot(Hamilton_CT) +
geom_sf(aes(fill = cut_number(POPULATION, 5)), color = NA, size = 0.1) +
scale_fill_brewer(palette = "YlOrRd") +
coord_sf() +
labs(fill = "Population")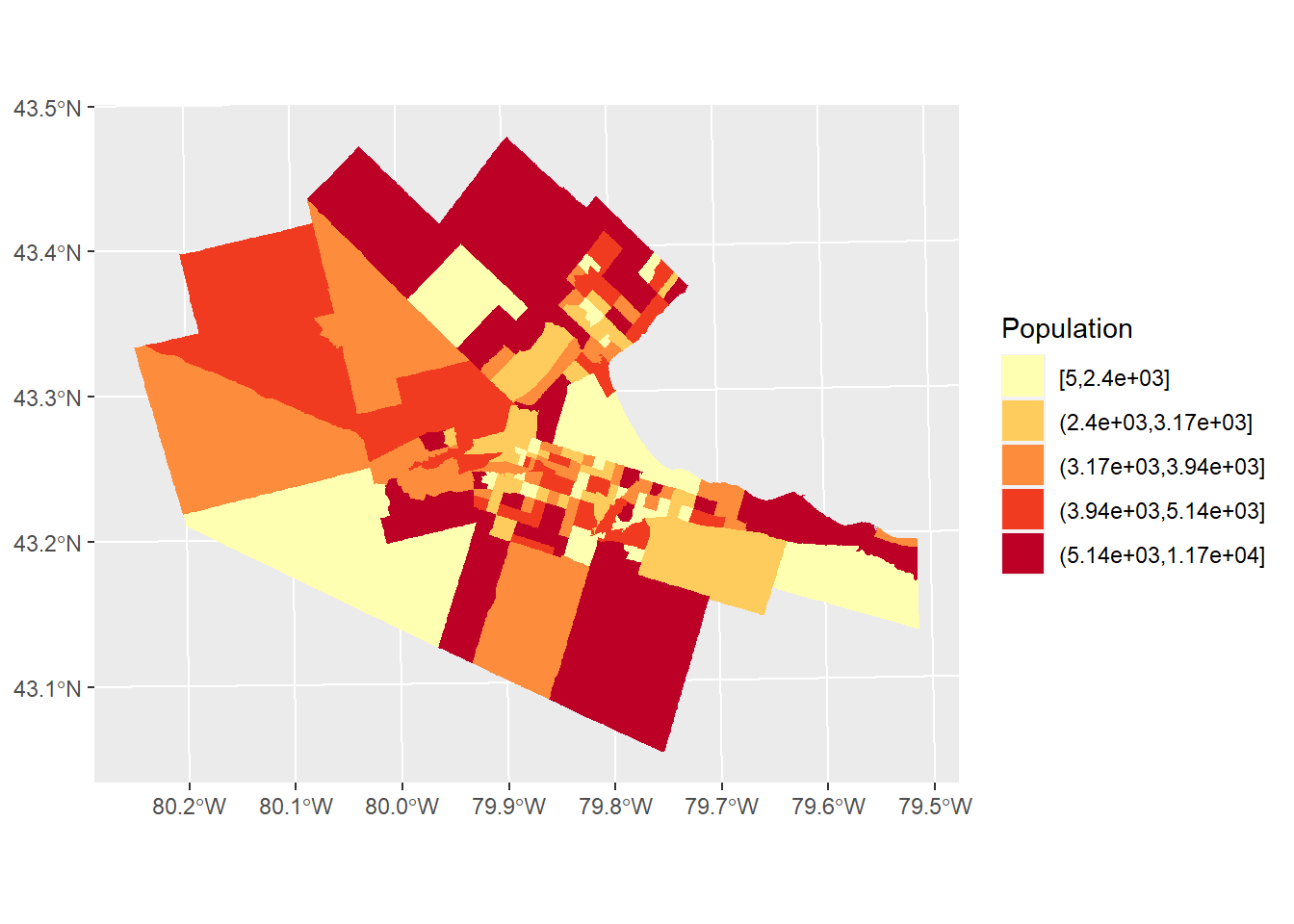
Inspect the map above. Would you say that the distribution of population is random, or not random? If not random, what do you think might be an underlying process for the distribution of population?
Often, creating a choropleth map using the absolute value of a variable can be somewhat misleading. As illustrated by the map of population by census tract in Hamilton, the zones with the largest population are also often large zones. Many process are confounded by the size of the zones: quite simply, in larger areas often there is more of, well, almost anything, compared with smaller areas. For this reason, it is often more informative when creating a choropleth map to use a variable that is a rate. Rates are quantities that are measured with respect to something. For instance population measured by area, or population density, is a rate:
# Note how the `cut_number()` is applied to population density rather than population like the figure above. This gives a more different, and perhaps more informative, of the distribution of population, by measuring population against area.
pop_den.map <- ggplot(Hamilton_CT) +
geom_sf(aes(fill = cut_number(POP_DENSITY, 5)), color = "white", size = 0.1) +
scale_fill_brewer(palette = "YlOrRd") +
labs(fill = "Pop Density")
pop_den.map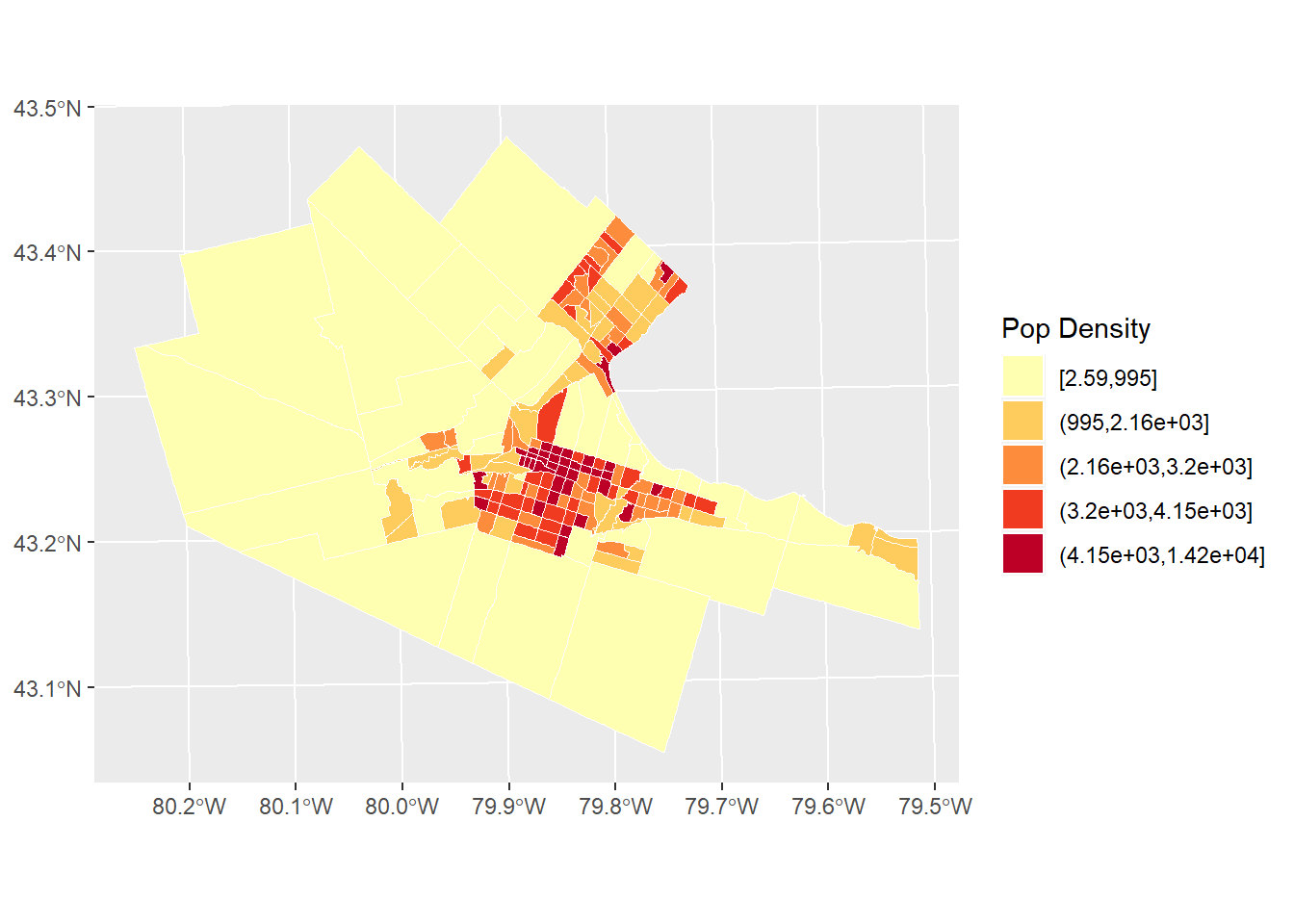
It can be seen now that the population density is higher in the more central parts of Hamilton, Burlington, Dundas, etc. Does the map look random? If not, what might be an underlying process that explains the variations in population density in a city like Hamilton?
Other times, it is appropriate to standardize instead of by area, by what might be called the population at risk. For instance, imagine that we wanted to explore the distribution of the population of older adults (say, 65 and older). In this case, if instead of normalizing by area, we used the total population instead, would remove the “size” effect, giving a rate:
#The "HAMILTON_CT" dataframe portions ages by category. For this choropleth map, we sum all age categories over 65, and then divide by total population. This measures the population of older adults against total population, to give a proportion (the rate out of a total).
ggplot(Hamilton_CT) +
geom_sf(aes(fill = cut_number((AGE_65_TO_69 +
AGE_70_TO_74 +
AGE_75_TO_79 +
AGE_80_TO_84 +
AGE_MORE_85) / POPULATION, 5)),
color = NA,
size = 0.1) +
scale_fill_brewer(palette = "YlOrRd") +
labs(fill = "Prop Age 65+")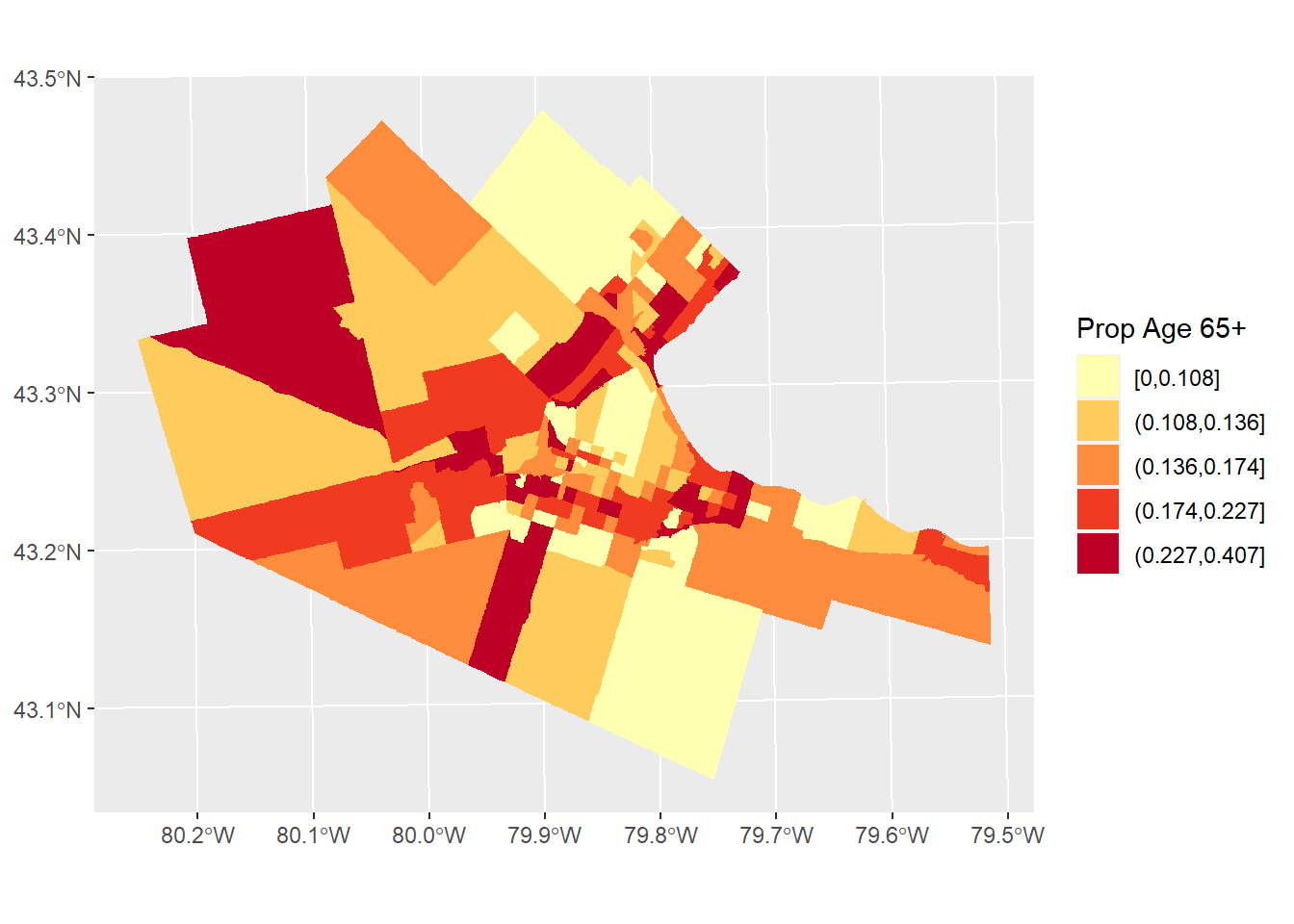
Do you notice a pattern in the distribution of seniors in the Hamilton, CMA?
There are a few things to keep in mind when creating choropleth maps.
First, what classification scheme to use, with how many classes, and what colors?
The examples above were all created using a classification scheme based on the quintiles of the distribution. As noted above, these are obtained by dividing the sample into 5 equal parts to give bottom 20%, etc., of observations. The quintiles are a particular form of a statistical summary measure known as quantiles. Another example of a quantile is the median, which is the value obtained when the sample is divided in two equal sized parts. Other classification schemes may include the mean, standard deviations, and so on. Essentially, a classification scheme defines a way to divide the sample for representation in a choropleth map.
In terms of how many classes to use, often there is little point in using more than six or seven classes, because the human eye cannot distinguish color differences at a much higher resolution.
The colors are a matter of style and preference, but there are coloring schemes that are colorblind safe (see here). Also, for communication purposes, there are conventions that assign values or meanings to colors. Maps showing results of elections often use the colors of political parties: this is such a widespread convention that it would be thoroughly confusing if the colors were reversed, more so than if just the colors were exchanged for others. Red is often associated with heat, concentration, or sometimes bad, whereas green is associated with good. Here is an interesting discussion of use of colors in visualization.
Secondly, when the zoning system is irregular (as opposed to, say, a raster, which is composed of pixels, regular tiles of consistent size), large zones can easily become dominant. In effect, much detail in the maps above is lost for small zones, whereas large zones, especially if similarly colored, may mislead the eye as to their relative frequency.
Another mapping technique, the cartogram, is meant to reduce the issues with small-large zones.
19.7 Visualizing Area Data: Cartograms
A cartogram is a map where the size of the zones is adjusted so that instead of being the surface area, it is proportional to some other variable of interest.
We will illustrate the idea behind the cartogram here.
In the maps that we created above, the zones are faithful to their geographical properties (subject to distortions due to geographical projection). Unfortunately, this feature of the maps obscured the relevance of some of the smaller zones. A cartogram can be weighted by another variable, say for instance, the population. In this way, the size of the zones will depend on the total population.
Cartograms are implemented in R in the package cartogram.
# The function `cartogram_cont()` constructs a continuous area cartogram. Here, a cartogram is created for census tracts of the city of Hamilton, but the size of the zones will be weighted by the variable `POPULATION`.
CT_pop_cartogram <- cartogram_cont(Hamilton_CT, weight = "POPULATION")Plotting the cartogram:
#We are using "ggplot" to create a cartogram for populations by census tact in Hamilton. Census tracts with a larger value are distorted to visually represent their population size. The number "5" after calling the population variable states that there will be 5 categories dividing population quantities.
ggplot(CT_pop_cartogram) +
geom_sf(aes(fill = cut_number(POPULATION, 5)), color = "white", size = 0.1) +
scale_fill_brewer(palette = "YlOrRd") +
labs(fill = "Population")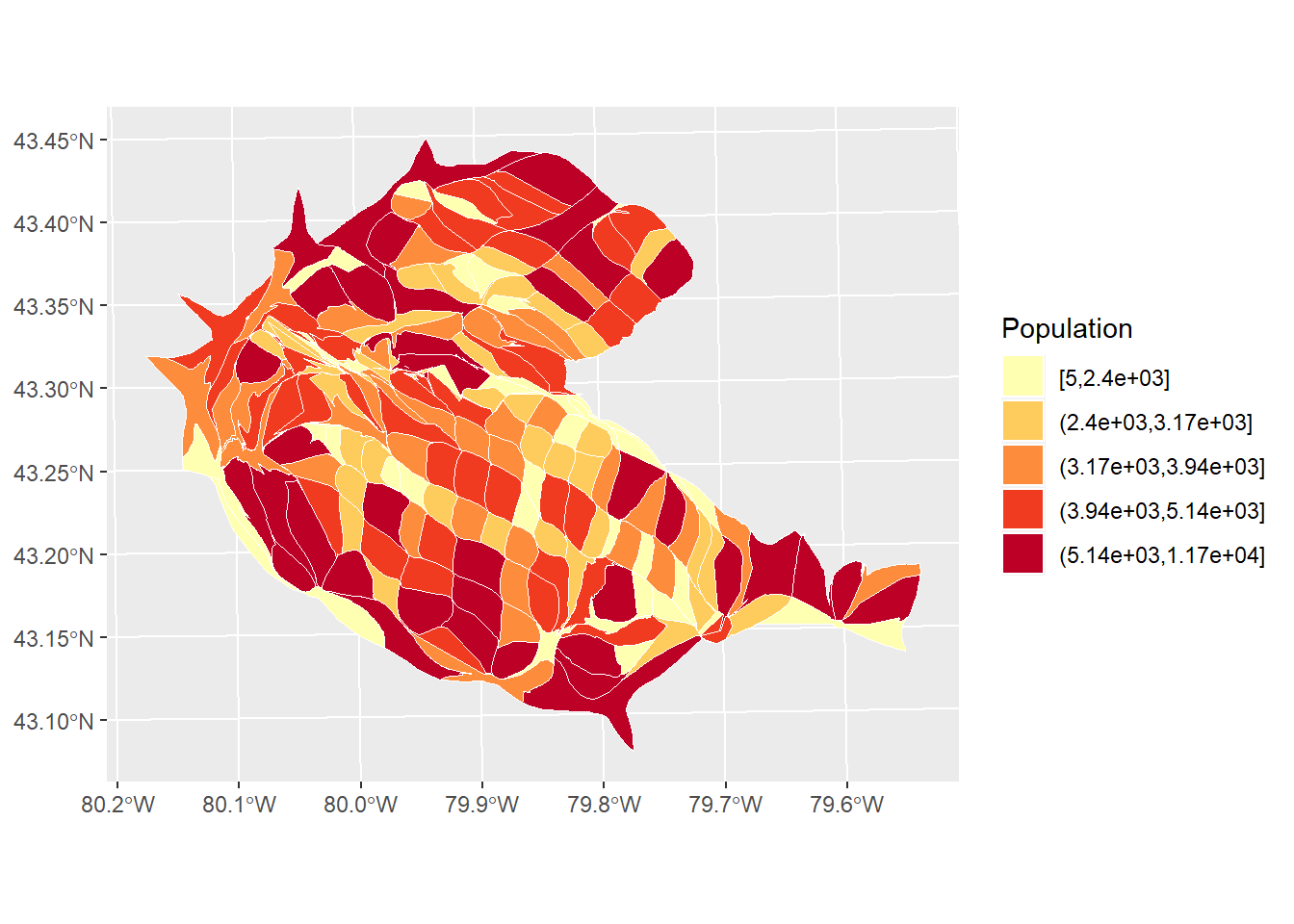
Notice how the size of the zones has been adjusted.
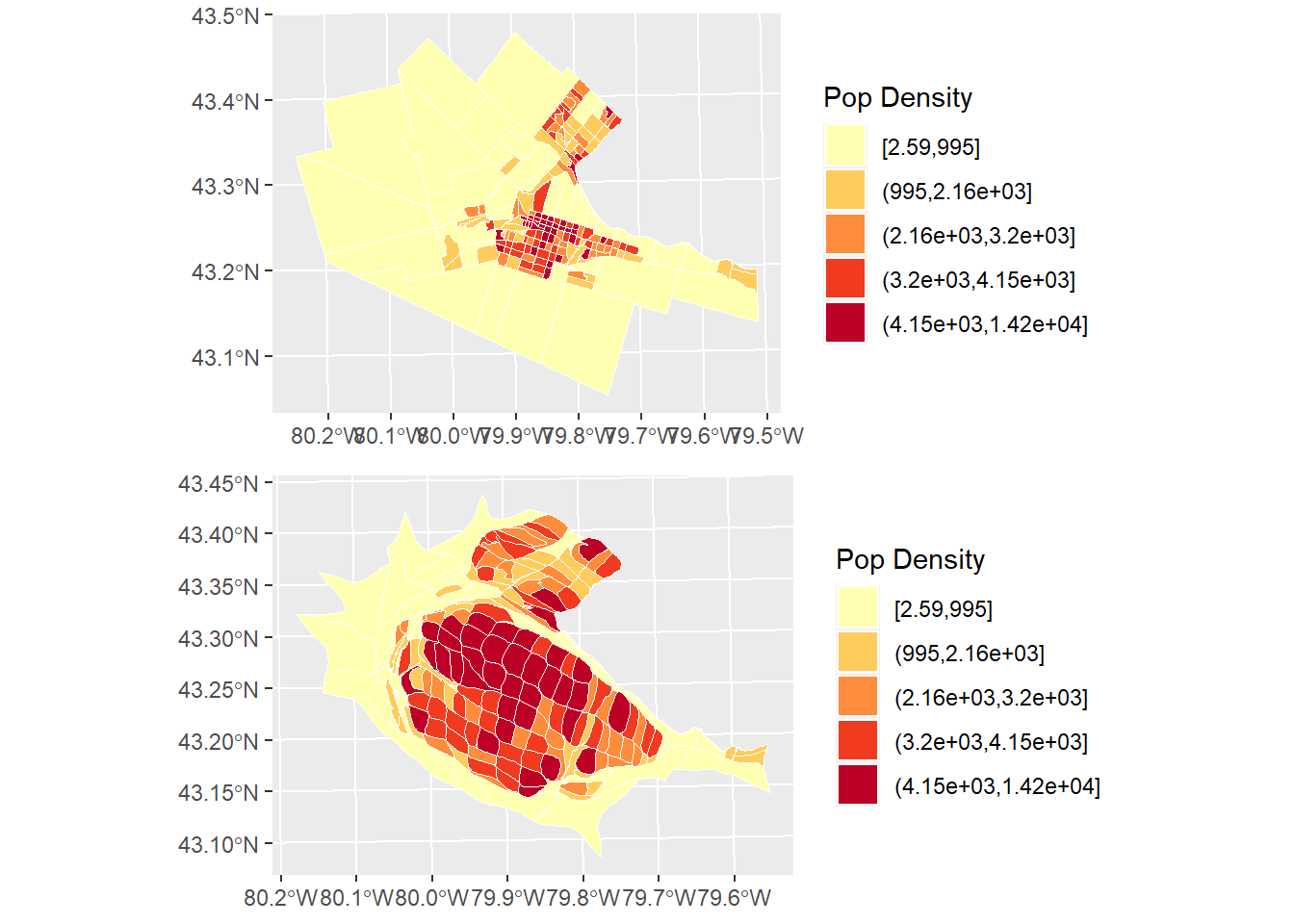
The cartogram can be combined with coloring schemes, as in choropleth maps:
Plot the cartogram:
pop_den.cartogram <- ggplot(CT_popden_cartogram) +
geom_sf(aes(fill = cut_number(POP_DENSITY, 5)),color = "white", size = 0.1) +
scale_fill_brewer(palette = "YlOrRd") +
labs(fill = "Pop Density")
pop_den.cartogram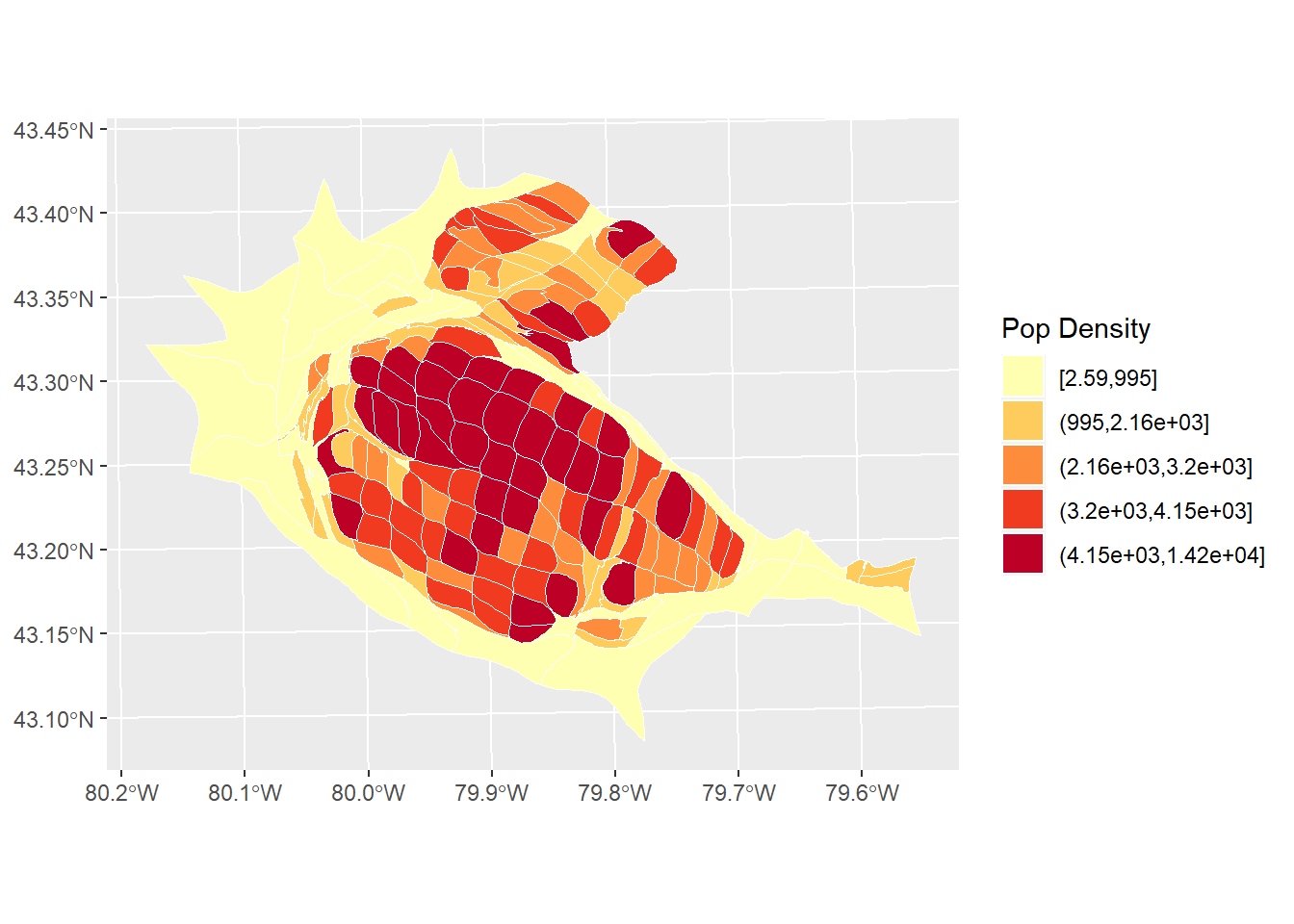
By combining a cartogram with choropleth mapping, it becomes easier to appreciate the way high population density is concentrated in the central parts of Hamilton, Burlington, etc.
This concludes this chapter.