Abstract
An important element of reproducible research is documenting all steps of the process, including data analysis. This vignette, developed for thepackr package (a minimal example of
package building), will show how to document data analysis in a
self-contained and reproducible document. To this end, the data
set energy_and_emissions (included in the
packr package) will be used.
Introduction
This vignette illustrate the use of the dataset and utility functions
included in the package packr. I collected this data set
initially to use in my course GEOG 3LT3: Transportation Geography. As
part of this course, students examine some trends in transportation,
including the use of energy and emissions. The objective of the practice
is two-fold:
On the side of technology, the students are learning to work with R Notebooks and R. For this reason, all code is documented so that the students can see how things are done.
On the side of transportation geography, the students are learning to discern trends in transportation.
Loading the data
To load the data, use the function data():
data("energy_and_emmisions")
#> Warning in data("energy_and_emmisions"): data set 'energy_and_emmisions' not
#> foundTo inspect the dataframe, use the function summary()
summary(energy_and_emissions)
#> Country Area Population PYear
#> Length:188 Min. : 54 Min. :5.292e+03 JULY 2017 EST.:188
#> Class :character 1st Qu.: 25618 1st Qu.:1.955e+06
#> Mode :character Median : 113098 Median :8.101e+06
#> Mean : 666756 Mean :3.847e+07
#> 3rd Qu.: 479278 3rd Qu.:2.558e+07
#> Max. :16377742 Max. :1.379e+09
#> GDPPC bblpd EYear CO2_1995
#> Min. : 145 Min. : 400 2014:148 Min. : 12
#> 1st Qu.: 1817 1st Qu.: 13000 2015: 34 1st Qu.: 936
#> Median : 5620 Median : 53000 2016: 6 Median : 6661
#> Mean : 13572 Mean : 490635 Mean : 121256
#> 3rd Qu.: 16148 3rd Qu.: 255500 3rd Qu.: 61534
#> Max. :100161 Max. :19530000 Max. :5294648
#> CO2_2005 CO2_2015 Continent
#> Min. : 14 Min. : 28 Africa :50
#> 1st Qu.: 1379 1st Qu.: 2153 Americas:41
#> Median : 8434 Median : 10062 Asia :47
#> Mean : 152549 Mean : 184978 Europe :36
#> 3rd Qu.: 62283 3rd Qu.: 75294 Oceania :12
#> Max. :6174717 Max. :10641789 NA's : 2The data frame consists of 10 variables. The variable definitions can be consulted in the help file:
?energy_and_emissions
#> No documentation for 'energy_and_emissions' in specified packages and libraries:
#> you could try '??energy_and_emissions'Are population and oil consumption related?
The dataframe includes information on population, GDP per capita,
energy consumption, and emissions for world countries. The consumption
of energy (in barrels per day) is for the country. We can plot these two
variables to see if there is a trend. We create a scatterplot with
x = Population and y = bblpd, so that the
values of population are mapped to the x-axis, and the values of energy
consumption are mapped to the y-axis:
# Simple Scatterplot
plot(energy_and_emissions$Population,
energy_and_emissions$bblpd,
main="Scatterplot Example",
xlab="Population ",
ylab="Barrels of oil per day ",
pch=19)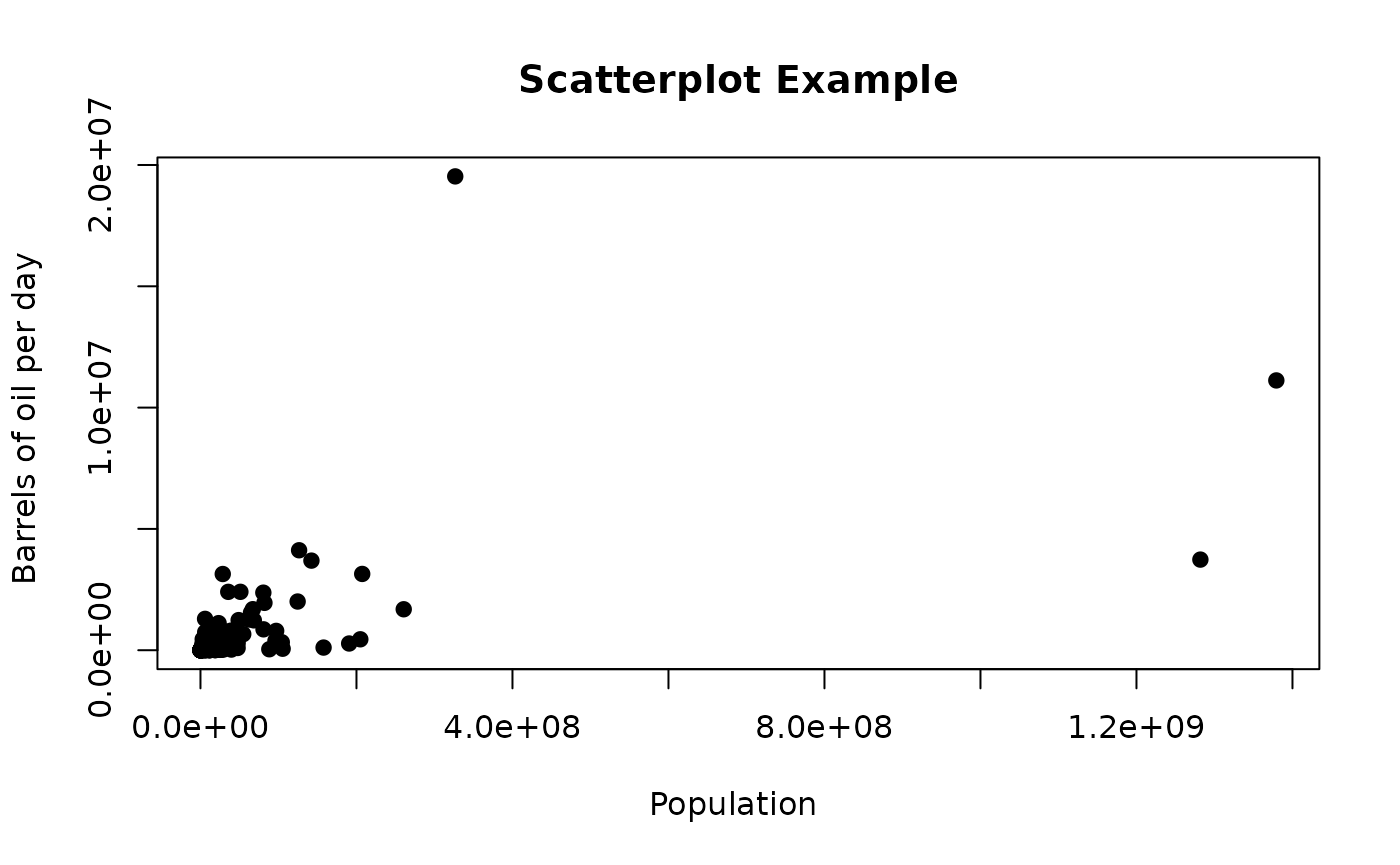
Not suprisingly, there is a strong association between these two variables, since countries with big populations will consume more energy than small countries with small populations. This is not very informative, because the underlying relationship is simply size.
What is the per capita consumption of oil by country?
Instead of exploring energy consumption by population, we will look
at energy consumption per capita. This is a more informative variable,
because it normalizes by size, and potentially can tell us something
about the intensity and/or efficiency of energy use.
However, energy consumption per capita is not one of the variables in
the dataset. We need to divide the variable bblpd by
Population to add this variable to the dataframe:
energy_and_emissions$EPC <- energy_and_emissions$bblpd/energy_and_emissions$PopulationCheck the descriptive statistics of EPC (energy
consumption in barrels per day per person):
summary(energy_and_emissions$EPC)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.0001308 0.0035039 0.0107354 0.0211934 0.0270790 0.2193948The maximum consumption is approximately 0.22 barrels per person per day. Which country is that?
energy_and_emissions[energy_and_emissions$EPC == max(energy_and_emissions$EPC), "Country"]
#> [1] "SINGAPORE"The country with the highest per capita oil consumption in the world according the the data is Singapore.
Are GDP per capita and energy consumption per capita related?
To answer this question, we can create a scatterplot of the two variables:
plot(energy_and_emissions$GDPPC,
energy_and_emissions$EPC,
main="Scatterplot Example",
xlab="GDP per capita ",
ylab="Energy consumption per capita (bbpd/population) ",
pch=19)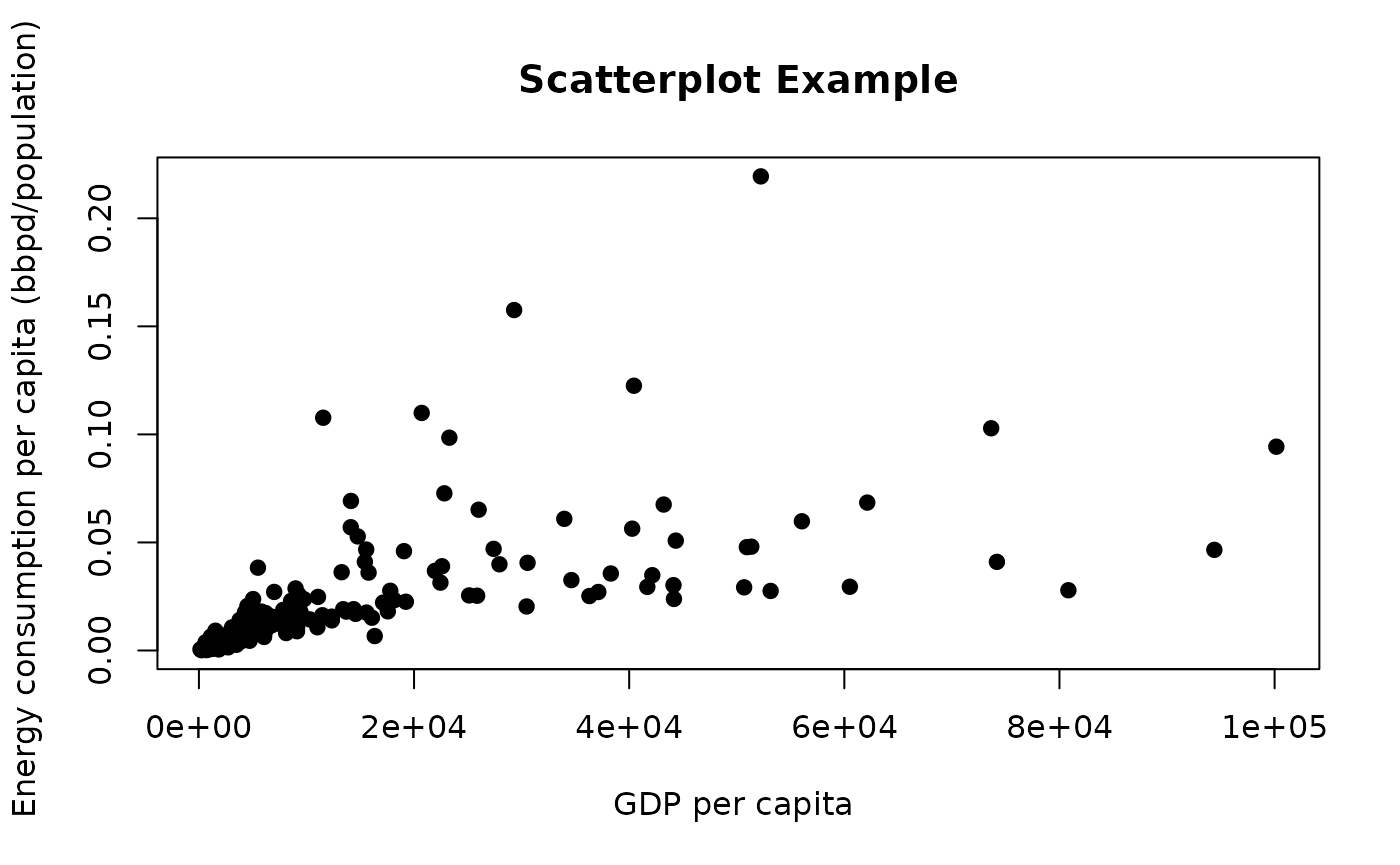
Calculate the correlation between these two variables:
cor(energy_and_emissions$GDPPC, energy_and_emissions$EPC)
#> [1] 0.6239777There is a moderately strong correlation between these two variables.
What do we learn from this analysis? And how would you extend this analysis?